近日,搭载英伟达 GB10 Grace Blackwell 超级芯片的 DGX Spark 桌面 AI 超算产品陆续上市开售,作为英伟达首款面向轻量化场景的 Grace Blackwell 架构产品,DGX Spark 不是单纯的性能堆叠,而是面向高性能工作站、桌面级 AI 开发和轻量化数据中心的整体解决方案,试图以“迷你机身 + 大模型支持”的组合,填补消费级显卡与大型数据中心之间的算力空白。
从今年初 NVIDIA 首次宣布代号 Project DIGITS,到第一方 FE 版本定价 3999 美元(约合 28533 元人民币),当时一度凭借 NUC 级的小巧体积与 1PetaFlop(1000TOPS)的 FP4 稀疏 AI 算力,点燃了桌面级高性能 AI 计算市场的讨论热情。现在,被重新命名为 DGX Spark 的桌面迷你 AI 工作站终于正式开售,华硕、戴尔和联想等上市的产品价格基本都在 32999 元以上。
随着 DGX Spark 的开售,让IT之家不禁想起另一款在相同赛道上已经站稳脚跟的产品 —— 基于 AMD 锐龙 AI Max+ 395 处理器的 Mini AI 工作站。同样主打“桌面级 AI 算力”,同样支持大模型本地推理,英伟达 GB10 与 AMD 锐龙 AI Max+ 395 究竟在架构设计、性能表现上有何差异?对于缺乏专业机房支持、预算有限且需要兼顾多场景使用的入门开发者而言,哪款产品更能满足“低门槛、高实用”的核心需求?今天不妨随小编来分析一下。

架构与性能对比:从芯片设计到实际算力的差异化呈现
要判断两款产品的适用场景,首先需深入其核心芯片的架构逻辑与实际性能表现。英伟达 GB10 与 AMD 锐龙 AI Max+ 395 虽同为“高性能计算芯片”,但在核心定位、架构设计与性能释放上,呈现出鲜明的差异化特征,而这些差异直接决定了它们对入门开发者的友好度。
英伟达 GB10:数据中心技术的桌面化应用
英伟达 GB10 超级芯片是其旗舰级 Grace-Blackwell 超级芯片的“小型化集成版本”,其设计目标是在有限的物理空间和功耗下(整机功耗约 240 瓦),承担起此前必须依赖大型数据中心系统的部分任务。
计算核心:GB10 的 CPU 部分是英伟达与联发科合作的产物,采用了 20 核 ARMv9.2 架构,具体由 10 个高性能 Arm Cortex-X925 核心与 10 个高能效 Arm Cortex-A725 核心组成。其 GPU 单元则拥有 6144 个 CUDA 核心,是 Blackwell 架构的精简版本。该 GPU 保留了对 FP4(4 位浮点)数据格式的支持,使其能够实现 1 PetaFLOP(即 1000 TOPS)的稀疏 AI 算力。在单精度(FP32)性能方面,其算力为 31 TFLOPS,与消费级显卡 RTX 5070 的水平相当。

统一内存与高速互联:该芯片配置了 128GB、256 位的 LPDDR5x-9400 统一内存,通过 2.5D 封装技术与 CPU、GPU 集成。CPU 与 GPU 通过带宽高达 600 GB/s 的 NVLink C2C(Chip-to-Chip)链路共享内存池,旨在减少传统 PCIe 总线带来的数据传输延迟。
专用网络与扩展功能:DGX Spark 集成了 ConnectX-7 200Gb/s 高速网卡。通过背部的 QSFP 端口,用户可以连接两台 DGX Spark 设备,从而将推理能力扩展至支持高达 4050 亿参数的模型。这进一步明确了其作为专业 AI 开发工具的定位。
软件生态:搭载定制版 DGX OS(基于 Ubuntu Linux),预装英伟达 AI 软件堆栈,仅支持 Linux 环境下的 AI 开发,不兼容 Windows 系统与 X86 架构软件。
AMD 锐龙 AI Max+ 395:端侧 AI 的“全场景全能选手”
与 GB10 的“单一场景优化”不同,AMD 锐龙 AI Max+ 395 的核心设计逻辑是“兼顾 AI 算力与全场景兼容性”,其架构围绕“Zen5 CPU+RDNA3.5 GPU+XDNA2 NPU”的三重计算单元展开,参数配置更贴近入门开发者的多维度需求:
计算核心:16 核 32 线程的 Zen 5 架构 CPU,最高加速频率高达 5.1GHz,配备 80MB 总缓存(16MB L2+64MB L3),性能接近桌面级处理器,可轻松应对数据预处理、多任务并发等需求;最高 40 单元的 RDNA 3.5 架构 iGPU(命名为 Radeon 8060S),带宽达 256GB/s,性能媲美移动版 RTX 4060/4070,支持图形密集型 AI 任务(如多模态模型推理);XDNA 2 NPU 峰值算力高达 50TOPS,原生支持微软 Windows 11 AI+PC 规范与 Copilot 等端侧 AI 应用。

内存架构:采用 AMD 独创的 UMA(Unified Memory Architecture)统一内存技术,最高支持 128GB 内存,其中最高 96GB 可专属分配给 GPU 作为专属显存,并再将 16GB 作为共享显存。这种动态调度机制无需频繁进行内存复制,彻底消除了传统“CPU 内存 + GPU 显存”分离架构的“数据搬运开销”,对大模型加载与推理效率的提升尤为明显。
软件生态:基于 X86 架构,默认支持 Windows 系统,可无缝兼容 Office、Photoshop 等日常软件,以及 TensorFlow、PyTorch 等主流 AI 开发框架,其开源 AI 软件框架 ROCm 近期也宣布对于 Windows 的支持。同时,AMD 锐龙 AI MAX+ 395 也原生适配 Ubuntu 系统,相信 AMD 395 更兼顾传统开发与 AI 创新需求。
那么,两大芯片在面对 AI 大模型本地运行时的实际性能表现如何呢?就在 10 月 16 日,第三方 YouTube 博主 Bijan Bowen 对 DGX Spark 和锐龙 AI Max+ 395 平台进行了性能对比实测,这里IT之家不妨引用一下他的实测数据,来给大家做一个参考:
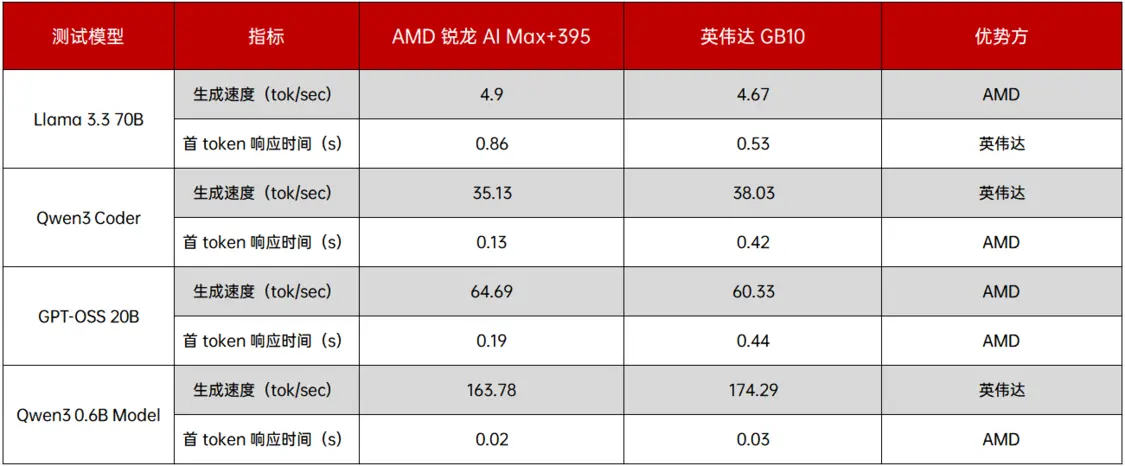
整体来看,在四个不同量级和类型的模型测试中,双方虽各有胜负,但 AMD 的表现整体上竟然还要稍微领先一些。以 Llama 3.3 70B 的测试为例,推理运行需要激活大量参数的稠密模型场景,AMD 以 4.9 tok / sec 的速度领先于英伟达的 4.67 tok / sec。这说明尽管英伟达拥有 CUDA 生态和更高的 FP4 算力,受限于带宽,在实际的 Tokens 生成速度表现上,AMD 的 Strix Halo 完全有能力正面抗衡。
在 4 个测试中的 3 个,AMD 平台都取得了更快的“首 token 生成时间”(time to first token),这意味着在交互式 AI 应用(如编码助手、聊天机器人)中,用户能更快地得到响应,体验可能更流畅。
综合来看,在入门开发者高频使用的中大型模型,尤其是 MoE 架构模型(Qwen3-30B-A3B、GPT-OSS 20B)上,AMD 锐龙 AI Max+ 395 的生成速度(435.13 tok / sec、64.69 tok / sec)均和英伟达 GB10(38.03 tok / sec、60.33 tok / sec)势均力敌,且首 token 响应时间除 Llama 3.3 70B 外均更短 —— 这意味着在实际开发中,AMD 平台能更快响应,减少开发者的等待时间。
因此整体来看,AMD 的性能表现更贴合入门群体的实际使用场景。
从生态到成本面面观,AMD 锐龙 AI Max+ 395 具有“入门友好型”优势
对于入门开发者而言,硬件性能仅是选择标准之一,生态兼容性、产品普及度与单位成本效益等等,也是非常关键的决策因素。那么从这些要素的层面来看,英伟达 GB10 与 AMD 锐龙 AI Max+395 相比究竟谁更有优势呢?下面我们继续来看。
生态兼容性:X86 / Windows 架构,无需妥协非 AI 需求
英伟达 DGX Spark 运行的是定制版 Ubuntu Linux。对于那些常年沉浸在 Linux 环境中的资深 AI 研究者来说,这或许如鱼得水。但对于绝大多数初创中小团队、入门开发者、学生或从其他领域(如 Web 开发、应用开发)转型而来的工程师而言,这反而成了一个比较高的门槛。他们的日常工作流 —— 无论是使用 Visual Studio、JetBrains 全家桶,还是 Adobe 创意套件,亦或是简单的 Office 办公,都深度绑定在 Windows 生态上。
毕竟,入门开发者的工作场景往往并非“纯 AI 开发”,多数人还需要兼顾日常办公、文档处理、传统编程甚至轻度设计任务,而这恰恰是 AMD 锐龙 AI Max+ 395 的核心优势所在 —— 基于 X86 架构与 Windows 系统,其生态成熟度远超英伟达 GB10 的 Arm / Linux 组合。
具体来看,AMD 锐龙平台可直接运行 Office、微信、浏览器等日常软件,无需额外配置;在开发工具层面,Visual Studio、PyCharm 等主流 IDE 均对 Windows 有完善支持,TensorFlow、PyTorch 等 AI 框架也已实现 Windows 环境的“一键安装”,新手无需花费大量时间学习 Linux 命令与环境配置。此外,AMD 还支持 WSL 子系统,若开发者需要使用 Linux 专属工具(如某些开源模型的编译环境),可在 Windows 系统内直接开启 Linux 终端,避免了“双系统切换”的繁琐。
总之,Windows 系统的普及度更高,生态健全性是天生优势。入门开发者不需要在‘AI 开发’与‘日常使用’之间做妥协,这正是 AMD 平台的核心价值之一。
终端产品普及度与市场成熟度
英伟达的 DGX Spark 及其合作伙伴产品,在 2025 年 10 月 15 日才刚刚“正式发售”。作为一个全新的平台(Arm+Linux 的桌面 AI 设备),其早期的市场表现、驱动程序稳定性、软件兼容性仍有待观察。
相比之下,搭载 AMD 锐龙 AI Max+ 395 的 Mini AI 工作站正处于一个“爆发”状态。截至 2025 年 10 月,搭载 AMD 锐龙 AI Max+ 395 的 Mini AI 工作站已有数十款产品正在热销,有不同的配置和价格区间,可满足不同预算的需求:
比如像希未 SEAVIV AideaStation R1、极摩客 GMKtec EVO-X2、零刻 Beelink GTR9 Pro、铭凡 MINIS FORUM MS-S1 MAX 等都提供了从 64GB 内存 + 1TB SSD 万元左右的配置(可支持 700 亿参数模型推理,适合预算有限的个人开发者),到 128GB 内存 + 2TB SSD 这种 15000 元左右的价位档的配置(支持 2000 亿参数模型本地部署,适合中小团队)。

再往上还有惠普 HP Z2 Mini G1a(21999 元),具备更稳定的散热设计与企业级售后,适合对可靠性要求较高的场景。总之开发者们可以有丰富的选择。
这些产品已在京东、天猫等电商平台正式开售,用户可直接购买并“开箱即用”,部分品牌还提供“预装 LM Studio、Gaia 等 AI 工具”的增值服务,进一步降低入门难度。这些产品早已在市场上销售数月,经过了早期用户的检验,形成了成熟的产品矩阵和消费者认知。
对于一个急于上手的开发者来说,AMD 方案提供了“开箱即用”的便利性和丰富的选择:从 9999 元的入门款到 21999 元的品牌工作站,从风冷到水冷,从紧凑型到可扩展型,丰俭由人。这种先发优势和市场成熟度,显然意味着更低的购买风险、更完善的社区支持和即时的生产力。
单位成本效益:AMD 每万元算力更高,性价比突出
对于入门开发者而言,“单位价格对应的推理性能”是衡量性价比的核心指标。结合上面我们引用的第三方测试数据与终端产品价格,我们可以清晰看到 AMD 锐龙 AI Max+395 的成本优势:
以 GPT-OSS 20B 模型(入门开发者常用的中大型模型)为例,在该博主测试中使用的 AMD 阵营的极摩客 GMKtec EVO-X2(14999 元)生成速度为 64.69 tok / sec,折算后“每万元对应的生成速度”约为 43.13 tok / sec;而英伟达 DGX Spark FE 版(28533 元)的生成速度为 60.33 tok / sec,“每万元对应的生成速度”仅为 21.14 tok / sec—— 也就是说,在相同预算下,AMD 平台能提供两倍以上的推理性能。如果以已经上市后的产品价格算,英伟达 DGX Spark 当前在电商平台的价格都在 32999 元以上,“每万元对应的生成速度”更是只有 18.28 tok / sec,而 AMD 平台能提供近 2.4 倍的推理性能。

此外,AMD 平台的“长期使用成本”也更低:Windows 系统下的软件多为免费或低价(如 Office 365 个人版年费仅 398 元),而 Linux 系统的部分专业工具(如某些商业 AI 优化软件)需单独付费;AMD 的生态伙伴 Ripple AI 还提供“远程测试平台”,开发者无需购买硬件即可体验算力,进一步降低了试错成本。
其他方面考量
除生态与成本外,我们也可以关注一下开发者们同样关注的“模型适配速度”、“硬件扩展能力”等这些问题上,目前 DGX Spark 桌面超算和搭载锐龙 AI Max+ 395 处理器的桌面 Mini AI 工作站的差别。
模型适配:AMD AI 团队通过前期的紧密协作,对主流模型实现“当天适配”—— 例如 GPT-OSS-120B 模型发布当天,AMD 平台即完成适配;对于 AI 初创企业的爆款模型,也能实现“零日响应”,确保开发者能及时体验最新模型。而英伟达 GB10 的模型适配信息尚未公开,仅提及“预装 AI 软件堆栈”,灵活性不足。
硬件扩展灵活:AMD 支持通过 USB4 接口实现多机串联,六联智能最近在中国国际信息通信展览会上做了一个六机并联的演示,专属显存可扩展至 576GB,满足更大规模模型(如 4000 亿参数)的推理需求;而英伟达 DGX Spark 仅支持通过 ConnectX-7 网卡实现双机互联,扩展方式单一且成本更高(仅单块 ConnectX-7 网卡价格又得 1W+)。
入门支持完善:AMD 联合 RIPPLE AI 打造了“AI 开发者支持平台”,提供“开箱即用”的开发环境(预装模型、工具链)、线上教程与社区论坛,新手可快速上手;还针对学生群体推出“高校支持计划”,提供硬件试用与课程合作,进一步降低学习门槛。
结语
总体来说,通过对架构、性能、生态和成本等各方面的分析,我们可以看出英伟达 DGX Spark 和基于 AMD 锐龙 AI Max+ 395 的迷你工作站是面向不同用户群体的解决方案。
英伟达 DGX Spark 凭借其专用的硬件设计和与 CUDA 生态的深度整合,为专业 AI 研究人员和深度绑定于英伟达生态系统的开发者提供了一个高性能的桌面工具。其较高的价格和特定的 ARM / Linux 操作系统环境,也决定了它的用户群体相对聚焦。
而 AMD 锐龙 AI Max+ 395 平台则提供了一个更为通用的解决方案。它的主要优势体现在以下几个方面:
平台通用性:基于成熟的 x86 / Windows 生态,既能作为一台高性能的通用工作站,也能满足大型 AI 模型的本地推理需求,兼顾了日常工作与开发的双重需要。
市场成熟度:市场上已有多个品牌提供相关产品,消费者拥有更丰富的选择空间。
成本效益:在关键的“单位价格推理性能”指标上具有明显优势,显著降低了本地部署 AI 大模型的硬件门槛。
开放生态:依托用户基数庞大的 Windows 平台,并通过与社区合作、举办开发者竞赛等方式,AMD 正在构建一个开放的开发者生态系统。

随着 AI 开发逐渐从“专业领域”走向“大众市场”,像 AMD 锐龙 AI Max+ 395 这样的“普惠型”产品,正成为推动 AI 平权的关键力量。对于想要踏入 AI 开发领域、却受限于预算与技术门槛的开发者而言,基于 AMD 锐龙 AI Max+ 395 的 Mini AI 工作站,无疑是当前阶段的最优选择 —— 它不需要你是 Linux 专家,不需要你有巨额预算,只需要你有创新想法,就能在桌面端开启属于自己的 AI 开发之旅。
【来源:IT之家】















