阿里云发布通义Qwen3-Next基础模型架构并开源80B-A3B系列:改进混合注意力机制、高稀疏度MoE结构
9 月 12 日消息,阿里云通义团队今日宣布推出其下一代基础模型架构 Qwen3-Next,并开源了基于该架构的 Qwen3-Next-80B-A3B 系列模型(Instruct 与 Thinking)。

通义团队表示,Context Length Scaling 和 Total Parameter Scaling 是未来大模型发展的两大趋势,为了进一步提升模型在长上下文和大规模总参数下的训练和推理效率,他们设计了全新的 Qwen3-Next 的模型结构。
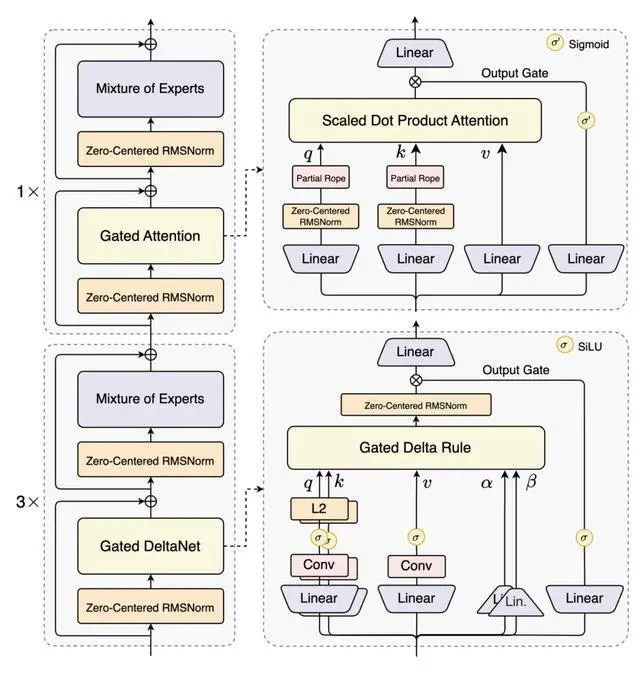
该结构相比 Qwen3 的 MoE 模型结构,进行了以下核心改进:混合注意力机制、高稀疏度 MoE 结构、一系列训练稳定友好的优化,以及提升推理效率的多 token 预测机制。
基于 Qwen3-Next 的模型结构,通义团队训练了 Qwen3-Next-80B-A3B-Base 模型,该模型拥有 800 亿参数(仅激活 30 亿参数)、3B 激活的超稀疏 MoE 架构(512 专家,路由 10 个 + 1 共享),结合 Hybrid Attention(Gated DeltaNet + Gated Attention)与多 Token 预测(MTP)。
IT之家从官方获悉,该 Base 模型实现了与 Qwen3-32B dense 模型相近甚至略好的性能,而它的训练成本仅为 Qwen3-32B 的十分之一不到,在 32k 以上的上下文下的推理吞吐则是 Qwen3-32B 的十倍以上,实现了极致的训练和推理性价比。
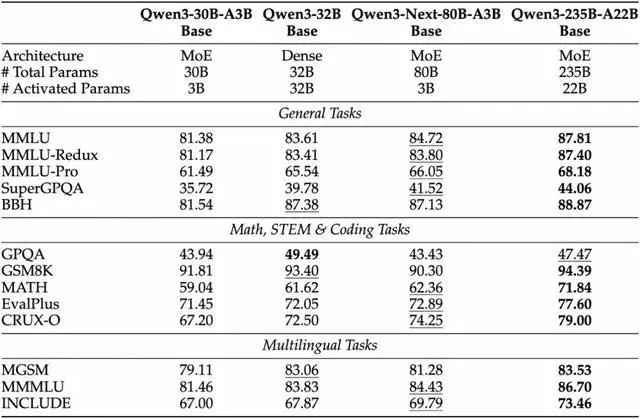
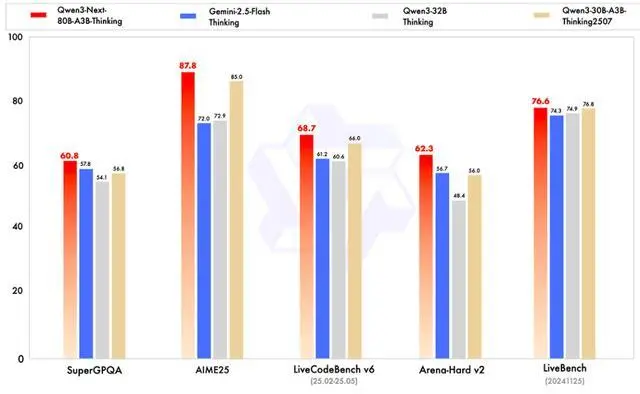
该模型原生支持 262K 上下文,官方称可外推至约 101 万 tokens。据介绍,Instruct 版在若干评测中接近 Qwen3-235B,Thinking 版在部分推理任务上超过 Gemini-2.5-Flash-Thinking。
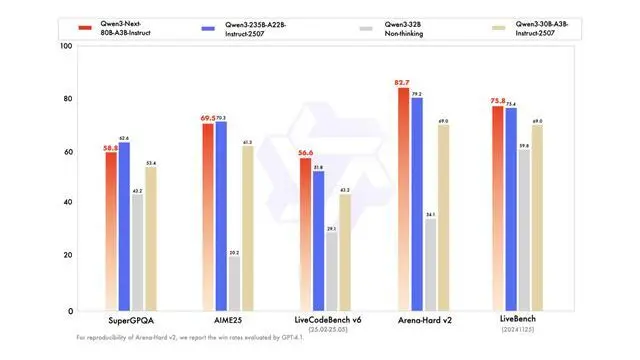
据介绍,其突破点在于同时实现了大规模参数容量、低激活开销、长上下文处理与并行推理加速,在同类架构中具有一定代表性。
模型权重已在 Hugging Face 以 Apache-2.0 许可发布,并可通过 Transformers、SGLang、vLLM 等框架部署;第三方平台 OpenRouter 亦已上线。
【来源:IT之家】




















