6月28日讯 当地时间周二,机器学习及人工智能领域开放产业联盟MLCommons披露两项MLPerf基准评测的最新数据,其中英伟达H100芯片组在人工智能算力表现的测试中,刷新了所有组别的纪录,也是唯一一个能够跑完所有测试的硬件平台。
(来源:英伟达、MLCommons)
MLPerf是由学术界、实验室和产业组成的人工智能领袖联盟,是目前国际公认的权威AI性能评测基准。Training v3.0包含8种不同的负载,包括视觉(影像分类、生物医学影像分割、两种负载的物体侦测)、语言(语音识别、大语言模型、自然语言处理)和推荐系统。简单来说,就是由不同的设备供应商提交完成基准任务所需要的时间。
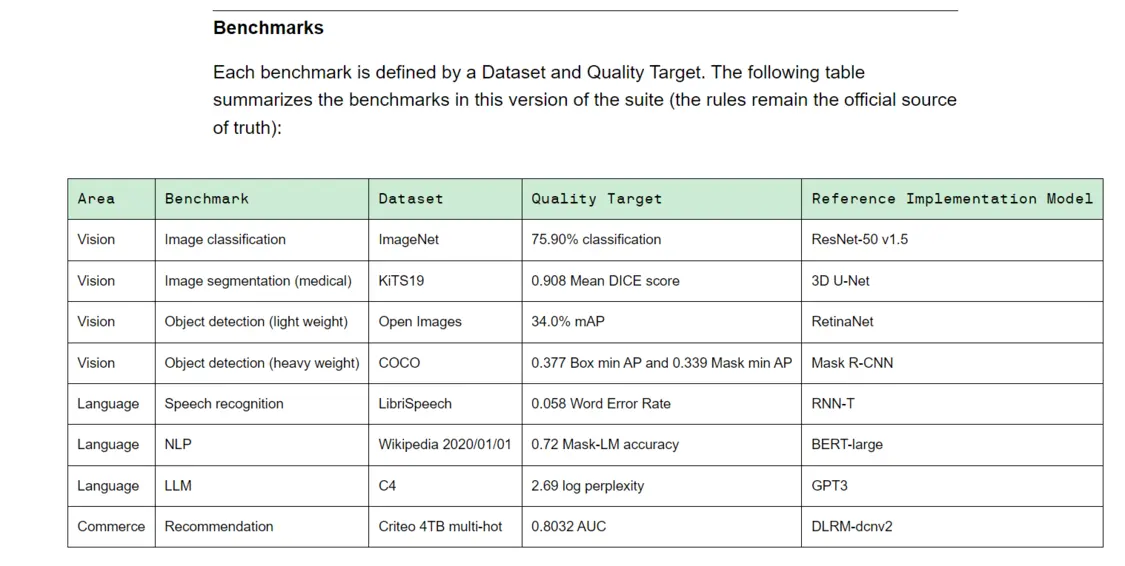
(Training v3.0训练基准,来源:MLCommons)
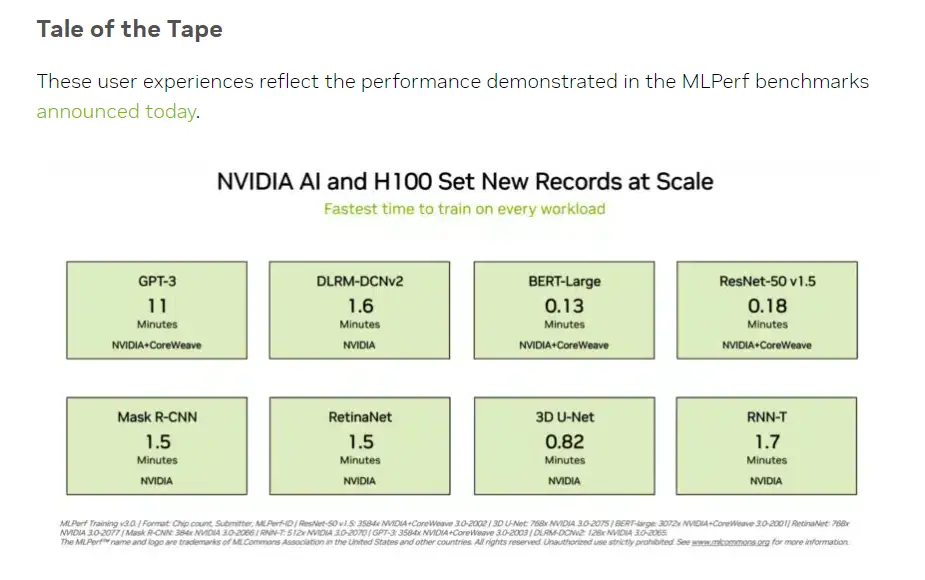
在投资者比较关注的“大语言模型”训练测试中,英伟达和GPU云算力平台CoreWeave提交的数据为这项测试设定了残酷的业界标准。在896个英特尔至强8462Y+处理器和3584个英伟达H100芯片的齐心协力下,仅仅花了10.94分钟就完成了基于GPT-3的大语言模型训练任务。
除了英伟达外,只有英特尔的产品组合在这个项目上获得评测数据。由96个至强8380处理器和96个Habana Gaudi2 AI芯片构建的系统中,完成同样测试的时间为311.94分钟。横向对比,使用768个H100芯片的平台跑完这个测试也只需要45.6分钟。
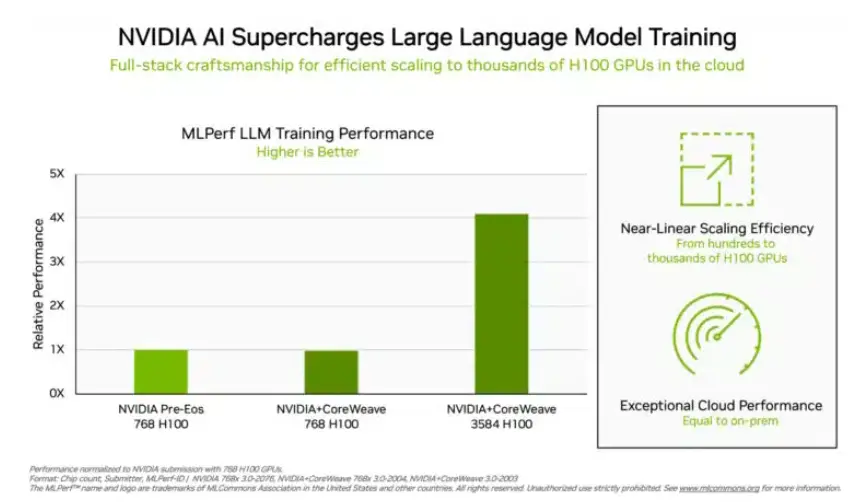
(芯片越多数据越好看,来源:英伟达)
对于这个结果,英特尔也表示仍有上升空间。理论上只要堆更多的芯片,运算的结果自然会更快。英特尔AI产品高级主管Jordan Plawner对媒体表示,接下来Habana的运算结果将会呈现1.5倍-2倍的提升。Plawner拒绝透露Habana Gaudi2的具体售价,仅表示业界需要第二家厂商提供AI训练芯片,而MLPerf的数据显示英特尔有能力填补这个需求。
而在中国投资者更熟悉的BERT-Large模型训练中,英伟达和CoreWeave将数据刷到了极端的0.13分钟,在64卡的情况下,测试数据也达到了0.89分钟。BERT模型中的Transformer结构正是目前主流大模型的基础架构。
【来源:财联社】




















