6 月 11 日消息,谷歌今天(6 月 11 日)发布公告,宣布推出 DiffusionGemma,是基于文本扩散机制的开放 AI 模型,相比较自回归模型在本地推理速度上提升了 4 倍。
IT之家注:自回归模型(Autoregressive Model)是当前主流的大语言模型架构(如 GPT、Gemini),按照从左到右的顺序逐个生成 Tokens。该架构在云端批处理场景下效率较高,但在本地推理时受限于内存带宽,存在计算资源浪费问题。
而扩散模型(Diffusion Model)通过从噪声中逐步去噪的方式生成输出。与自回归模型逐个生成 token 不同,扩散模型并行处理所有 token,逐步优化整体输出质量,在本地低带宽计算环境下具有显著的推理速度优势。
开源方面,该模型能力与其他 Gemma 4 模型相当,但推理效率显著更高。该模型采用 Apache 2.0 许可证开源,用户可从 Hugging Face 下载模型权重。
质量方面,模型还支持迭代优化,能在生成过程中主动纠正错误,输出更加稳定一致。采样速度达到 1479 tokens / 秒,开销仅 0.84 秒,生成效率显著提升。
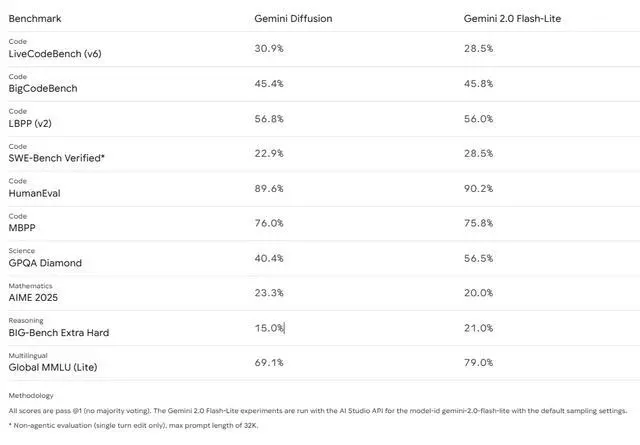
性能方面,代码生成上,LiveCodeBench 达 30.9%,BigCodeBench 达 45.4%,HumanEval 达 89.6%,与 Gemini 2.0 Flash-Lite 互有胜负。
数学能力表现亮眼,AIME 2025 取得 23.3%,超越对比模型的 20.0%,展现出扩散架构在推理任务上的潜力。
不过模型在部分基准上仍存短板。科学推理 GPQA Diamond 仅 40.4%,明显低于对比模型的 56.5%;推理能力 BIG-Bench Extra Hard 为 15.0%,同样落后于 21.0%。
速度方面,英伟达在官方博文中指出,该模型的扩散设计,能充分发挥英伟达 GPU 的 Tensor Core 并行计算能力。
在单块 H100 GPU 上,DiffusionGemma 达到每秒 1000 个 token 的生成速度;在 DGX Spark 上为每秒 150 个 token;在 DGX Station 上可达每秒 2000 个 token,约为同等条件下自回归模型的 4 倍。

【来源:IT之家】