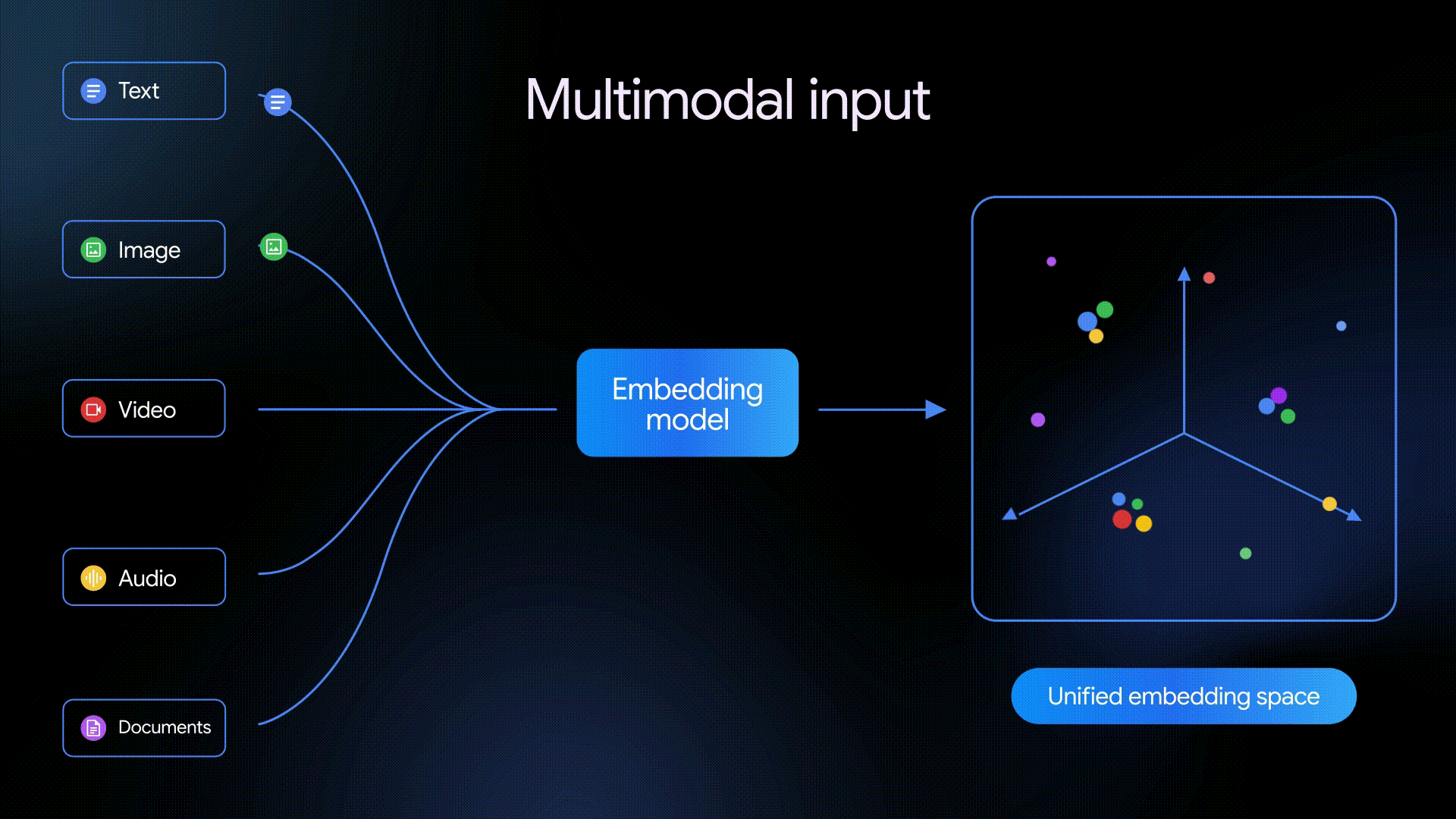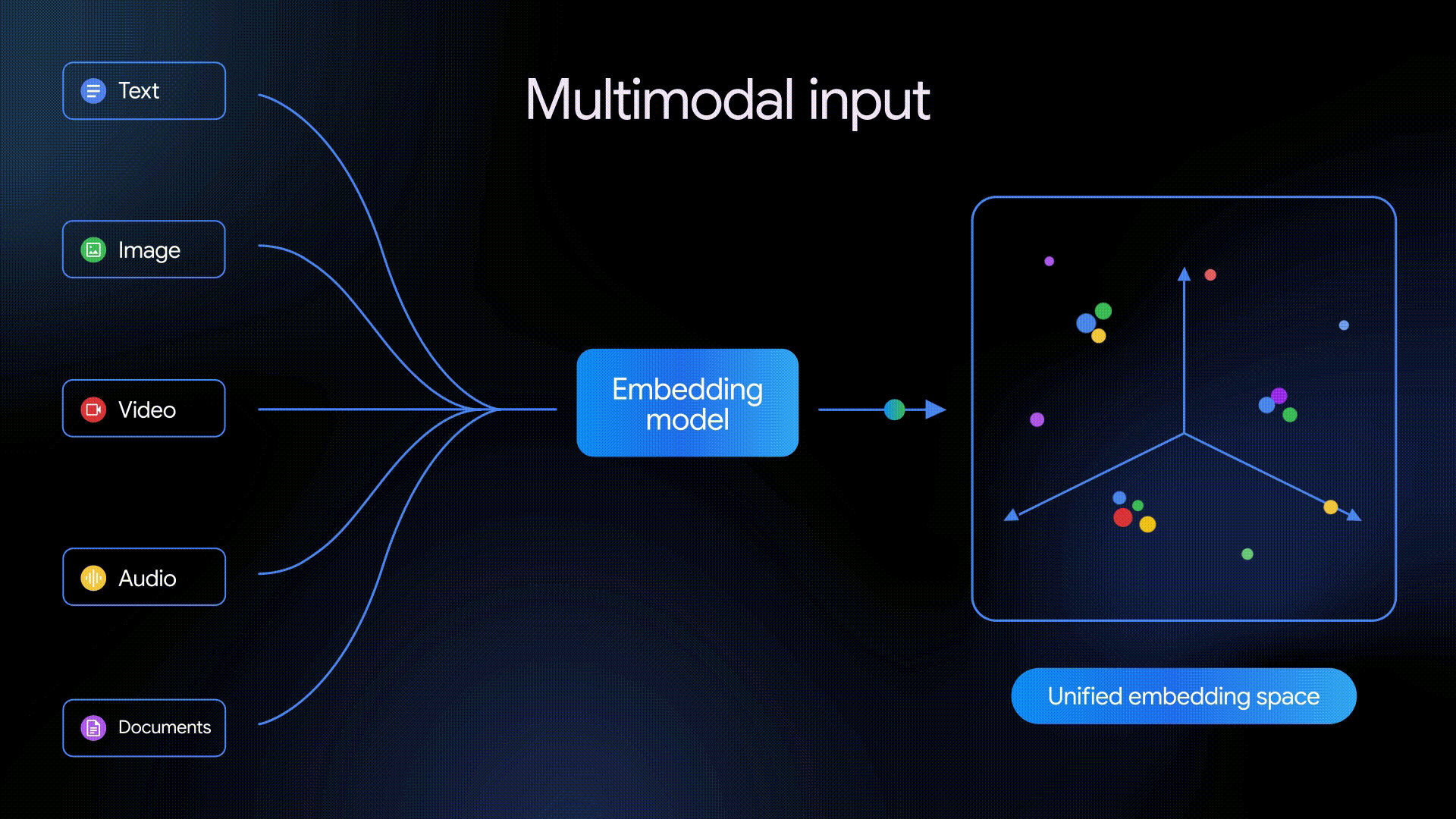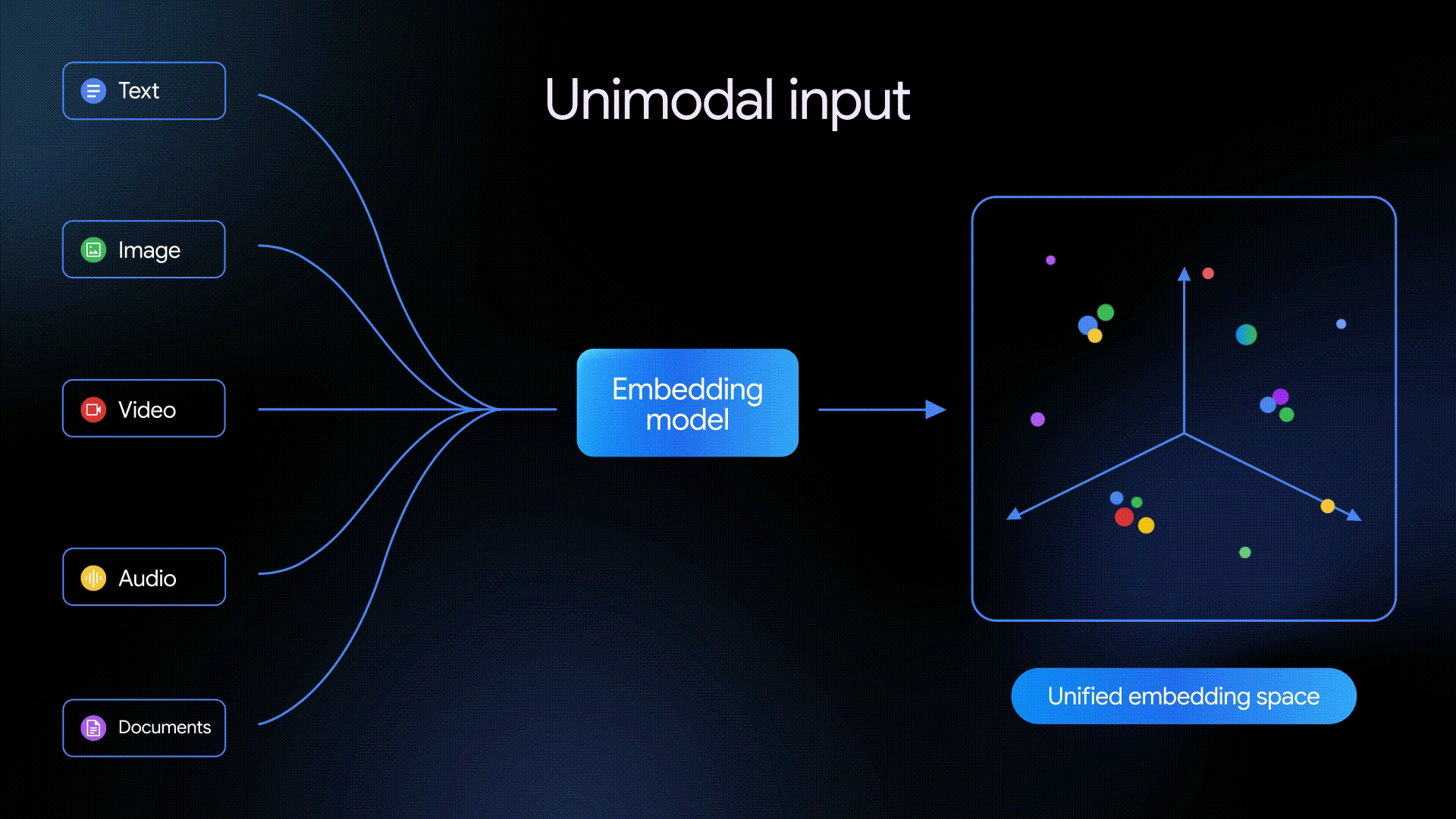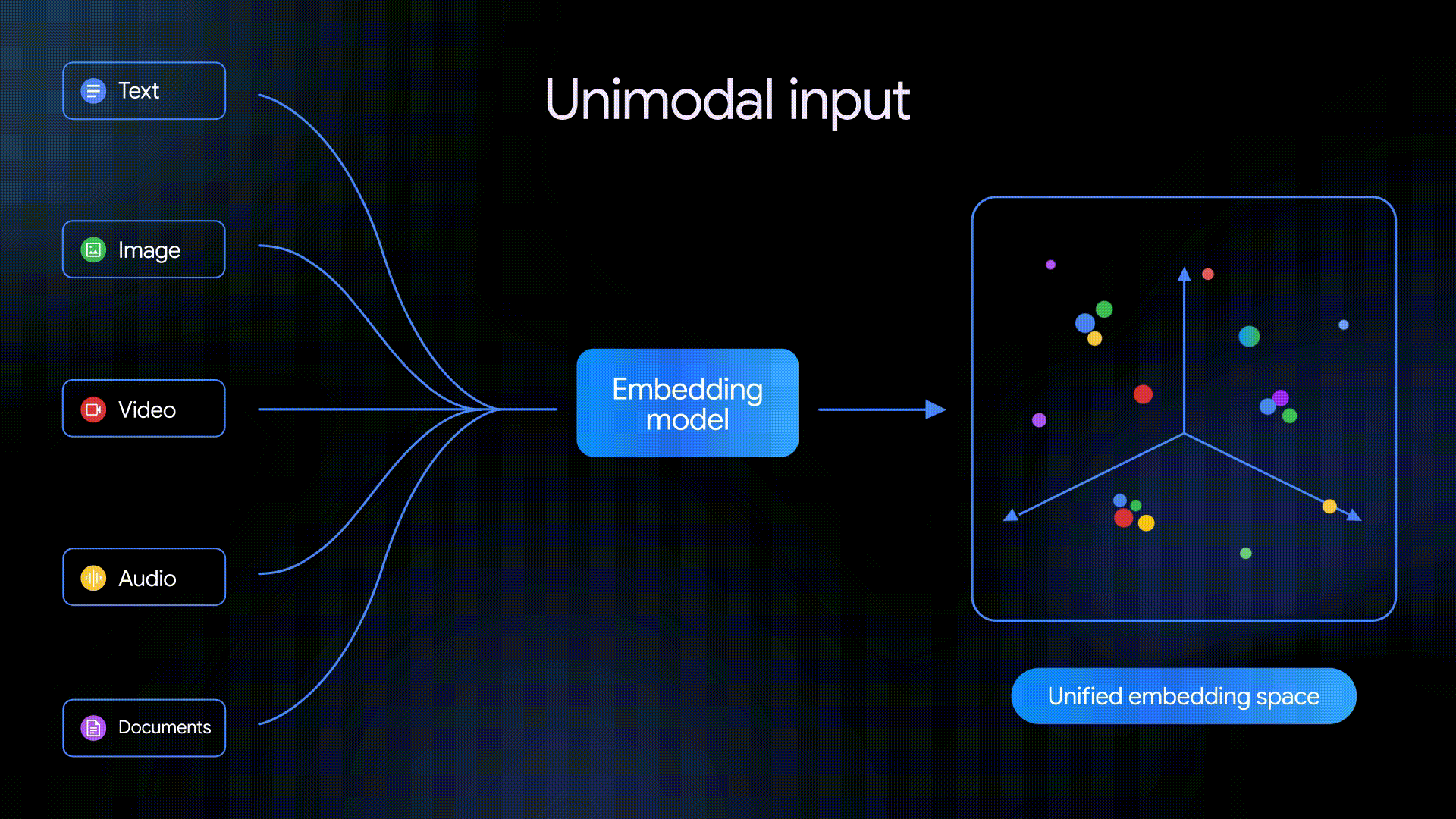
3月10日,谷歌DeepMind推出Gemini Embedding 2,这是该公司首个原生多模态嵌入模型,将文本、图像、视频、音频及文档统一映射至单一嵌入空间,标志着AI嵌入技术迈入全模态融合的新阶段。

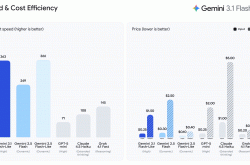
Gemini Embedding 2支持超100种语言的语义理解,并在文本、图像及视频任务的基准测试中超越现有主流模型,同时引入了此前嵌入模型所欠缺的语音处理能力。
该模型现已通过Gemini API及Vertex AI进入公开预览阶段,开发者可即时接入。
对于企业用户而言,该模型的发布直接降低了构建多模态检索增强生成(RAG)、语义搜索及数据分类系统的技术门槛,有望简化此前需跨模态分别处理的复杂数据管道。
全模态统一:从文本扩展至五类媒体形式
Gemini Embedding 2基于Gemini架构构建,将嵌入能力从纯文本扩展至五类输入形式:
文本支持最多8192个输入token;
图像每次请求最多处理6张,支持PNG及JPEG格式;
视频支持最长120秒的MP4和MOV文件;
音频可直接摄入并生成嵌入向量,无需经过中间文本转录步骤;
文档则支持最多6页的PDF文件直接嵌入。
区别于逐一处理单一模态的传统方式,该模型支持交错输入,即在单次请求中同时传入图像与文本等多种模态组合,使模型能够捕捉不同媒体类型之间复杂而细微的语义关联。
Gemini Embedding 2延续了谷歌此前嵌入模型中采用的Matryoshka表示学习(MRL)技术。该技术通过"嵌套"方式动态压缩向量维度,使输出维度可从默认的3072灵活缩减,帮助开发者在模型性能与存储成本之间取得平衡。
基准测试领先,语音能力为新亮点
谷歌表示,Gemini Embedding 2在文本、图像及视频任务的基准测试中均优于当前主流竞品模型,并将其定位为多模态嵌入领域的新性能标杆。
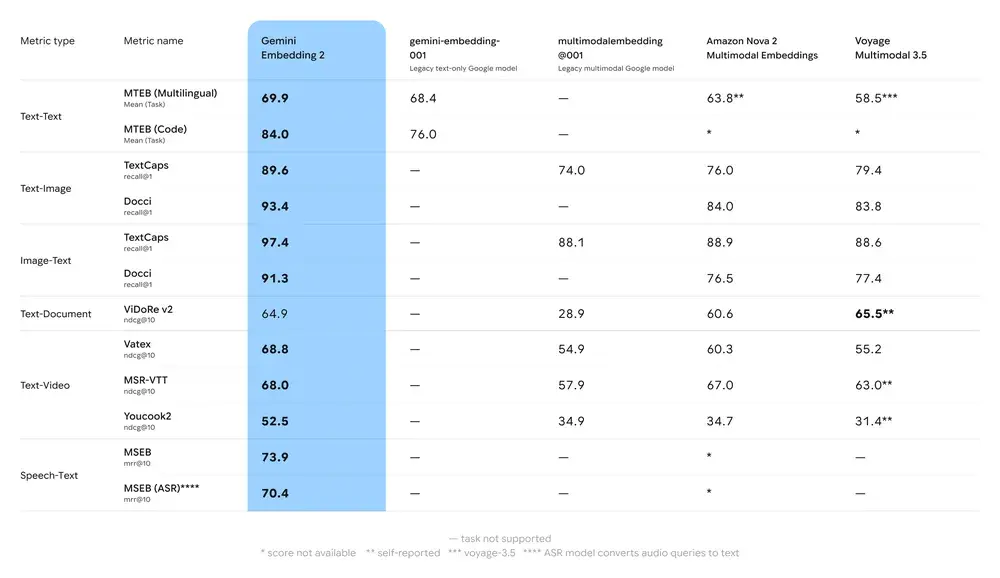
谷歌建议开发者根据应用场景选择3072、1536或768三档维度,以获得最优质的嵌入效果。这一设计对于需要大规模部署嵌入向量的企业尤为重要,可在不显著牺牲精度的前提下有效控制基础设施成本。
在能力覆盖方面,该模型引入了此前同类模型普遍缺失的原生语音嵌入能力,无需借助语音转文字的中间环节即可直接处理音频数据。
谷歌指出,嵌入技术已广泛应用于其多款产品之中,覆盖RAG场景下的上下文工程、大规模数据管理以及传统搜索与分析场景。
目前已有部分早期访问合作伙伴开始基于Gemini Embedding 2构建多模态应用,谷歌称这些用例正在兑现该模型在高价值场景中的实际潜力。
【来源:华尔街见闻】