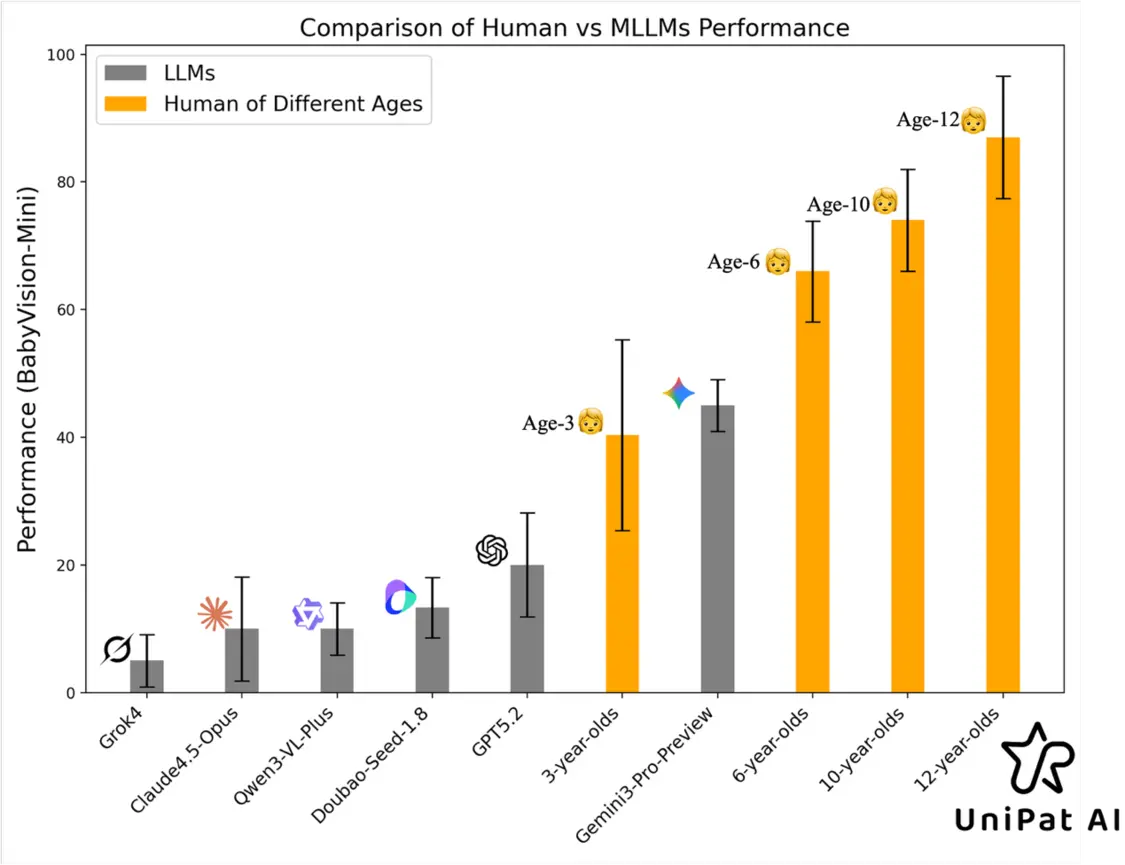
1月12日,近日,红杉中国旗下评测体系xbench与UniPat AI团队联合发布全新多模态理解评测集BabyVision,旨在系统评估大模型在不依赖语言提示下的纯视觉基础能力。评测结果显示,当前主流多模态大模型在该测试中整体表现落后于3岁幼儿水平。
该评测集将视觉能力划分为精细辨别、视觉追踪、空间感知、视觉模式识别四大类别,共涵盖22项子任务、388道题目。测试严格控制语言依赖,确保题目信息无法被完整“文本化”,从而考察模型真正的视觉理解能力。
最终评测结果显示,在BabyVision Full上,研究团队引入了人类基线,16位至少本科背景的测试者完成全量388题,人类准确率达94.1%。
再看模型,表现最佳的闭源模型Gemini3-Pro-Preview准确率为49.7%,GPT-5.2为34.8%,国内模型Doubao-1.8为30.2%,开源模型Qwen3VL-235B-Thinking为22.2%。多数模型得分明显低于3岁儿童平均水平。
研究团队指出,许多视觉信息本质上是“不可言说”的,一旦被压缩为语言描述就会丢失关键细节,导致模型在需要连续追踪、空间想象、几何归纳等任务中表现显著落后。为此,团队同时推出生成式评测版本BabyVision-Gen,要求模型以画图、标注等视觉方式作答,现阶段得到的结论为:
生成式推理在视觉追踪、精细辨别等VLM易翻车任务上出现“更像人类”的行为(会真的去画轨迹、做标注),但整体仍然缺乏稳定到达完全正确解的能力。
BabyVision的发布为多模态大模型与具身智能的发展提供了可量化、可诊断的评估工具,显示出当前视觉基础能力仍是AI迈向通用智能的关键短板。
【来源:凤凰网科技】

















