大模型推理的下一程,胜负手不再只是算力。推理的瓶颈,从算力转向了显存。
当 Prefill 与 Decode 挤在同一个实例上,Prefill 的计算峰值抢占算力,Decode 的 KVCache 访存挤占带宽,两者互相拖累——首 token 延迟降不下来,token 间延迟抖动不止。而随着多轮对话让 KVCache 持续膨胀、长上下文把它推向极限、Agent 场景下它甚至需要跨会话流转,显存压力进一步加剧。这就是 PD 分离架构成为行业共识的根源:把 Prefill 和 Decode 拆到不同实例上,各按特征独立优化、弹性伸缩。
但分离带来一个新问题:Prefill 生成的 KVCache 如何高速搬到 Decode实例 ?如果传输不够快,分离的收益就会被延迟吃掉。更进一步,生产场景还需要 KVCache 跨实例共享、按需池化、分层存储,而不仅仅是一搬了之。
Mooncake 正是为解决这一问题而生。作为月之暗面和清华大学的开源项目,已被 vLLM、SGLang、Dynamo 集成为 PD 分离场景的 KV Connector,在 Agent 负载上实现了数倍吞吐提升。阿里云、英伟达等都在围绕这一架构构建生产能力。
曦望Sunrise,是首批从硬件层面深度适配 Mooncake 的国产 GPU 厂商之一——从 Transfer Engine 的 KVCache 跨节点高速传输,到 Mooncake Store 的分布式 KVCache 池化管理,曦望的适配贯穿了 KVCache 传输与管理的完整链路,真正让分离式推理与缓存池化在国产算力上落地。
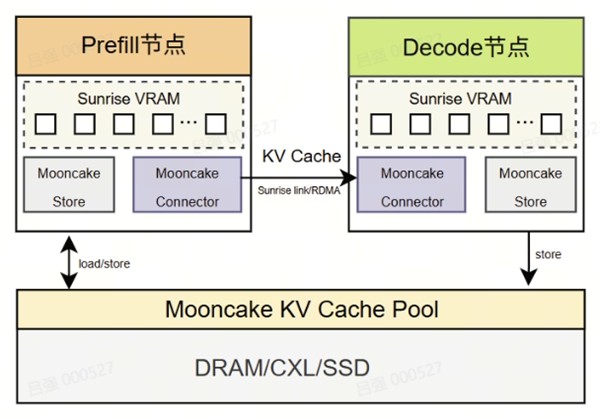
第一道硬仗:跨节点传输KVCache
PD 分离之后,Prefill 到 Decode 之间的 KVCache 搬运就是第一道硬仗。曦望芯片原生支持 GPUDirect RDMA(GDR),网卡可以直接读写 GPU 显存,跨节点搬运 KVCache 无需经主机内存中转。传统路径下,数据要先从设备拷到主机,再由 CPU 发起 RDMA,对端再从主机拷回设备——两次内存跳板,双倍延迟。而 GDR 让这变成一步到位的零拷贝,Prefill 节点生成的 KVCache 可以以接近硬件极限的带宽直达 Decode 节点的显存。
节点内,曦望自研的 Sunrise Link 片间互联提供高速跨卡通道。一次 Prefill 产生的 KVCache 动辄数 GB,需要在多张卡间快速聚合再发出——曦望的片间拓扑感知选路和多端口条带化并行,确保这些大块 KVCache 在卡间流转时不浪费一丝带宽。PD 分离的成败,往往就在这几个毫秒之间。
KVCache 池化:让显存从"独占"走向"共享"
搬得快还不够,还要存得聪明——这就是 KVCache 池化。
一个真实的生产环境往往运行着数十个推理实例,每个实例各自管理显存,KVCache 用完即弃——即便另一个实例正在处理相同的 prompt,也得从头算一遍。Mooncake Store 把分散在各实例的显存、主机内存乃至 SSD 汇聚成统一的 KVCache 缓存池:实例间可复用同一份 KVCache,避免重复计算;流量高峰时可弹性扩容、低谷时缩容而不丢失缓存;模型迭代时可原地升级,保留已积累的缓存。从显存到主机内存到 SSD,一条完整的分层缓存链路,让有限的硬件发挥出更大的承载力。
曦望对 Store 层的适配,让曦望 GPU 的显存能够作为这个缓存池的一部分被统一调度。在 Agent 多轮对话、长上下文推理成为常态的今天,这种池化能力直接决定了推理服务能不能在有限硬件下扛住更高的并发、更长的上下文、更复杂的交互链路。池化的本质,是把每一份算力都用在刀刃上。
硬件实力,是这一切的底气
PD 分离和 KVCache 池化不是纯软件能力——它们的天花板,由硬件决定。
原生 GDR 支持。并非所有国产 GPU 都支持 GPUDirect RDMA——这要求 GPU 在硬件层面允许网卡通过 PCIe P2P DMA 直接读写显存,绕过 CPU 和主机内存。曦望芯片原生具备这一能力,这是 PD 分离架构能跑出实际收益的根基。
自研片间互联。曦望没有依赖标准互联方案,而是自研 Sunrise Link 片间互联架构,配合 Tang Runtime 软件栈,构建了从显存注册、拓扑发现到跨卡 P2P 拷贝的完整节点内传输能力,让多卡间的 KVCache 流转带宽逼近互联硬件极限。
全栈软件适配能力。让一个以 CUDA 为中心的开源框架跑在自研硬件上,不是改几个接口就能完成的。曦望在运行时兼容层、设备上下文管理、内存分配器、并发锁调度等多个层面做了深度适配,在厂商运行时能力不足处自行补齐、多层回退,保证系统在真实生产环境中的鲁棒性。同一份 Mooncake 二进制,在曦望设备上按需加载自研运行时,在其他硬件上不受影响——这种工程能力,体现的是一家芯片公司对软件栈的掌控深度。
能把芯片造出来是一回事,能让芯片在分离式推理、KVCache 池化这些前沿架构中跑出实际价值,是另一回事。曦望做到了后者。
国产推理新范式,正在成型
当下,分离式推理已成为工业标配,Mooncake 正在成为这一范式的事实标准。而曦望,是率先从硬件底层深度适配这一架构的国产 GPU 厂商之一。
当 Prefill 和 Decode 可以跨节点分离部署、各自弹性伸缩,当 KVCache 可以跨实例共享复用、按需池化流转,当这一切都建立在原生 GDR 零拷贝和自研片间互联的硬件底座之上——曦望向行业证明的是:国产 GPU 不仅能在传统推理场景中跑通,更能支撑分离式推理、KV Cache池化这类下一代生产架构。
推理解耦的浪潮已经到来。曦望与 Mooncake 的这次结合,是国产算力承接这一浪潮的一个回答——不喊口号,把生产级的问题,一个一个解决掉。这不是终点,而是起点。当国产 GPU 能够深度参与定义推理架构的未来,一个不被单一厂商绑定的国产大模型算力底座,正在从蓝图走向现实。















