时序数据过去常被看作监控系统里的“指标数据”:写得快、存得下、能查曲线就够了。但在工业、交通、能源和城市治理场景里,时间数据正在进入调度决策、故障预测和综合研判链路。它不再只是连续上报的数值,而是业务运行过程本身。
这也改变了时序数据库的评价标准。单点写入吞吐仍然重要,但真正能进入核心系统的时序能力,还要经得住高基数写入、复杂查询、分布式扩展和多模数据关联。

时序数据的压力首先来自规模
时序数据库的第一道门槛是写入。工业设备、列车、船舶、传感器、站点和采集终端,会以秒级甚至更高频率持续上报数据。采集点数量一旦从百万级走向千万级,数据库面对的就不是普通“插入压力”,而是高基数、持续写入、长周期留存叠加在一起的系统压力。
在TSBS测试中,测试环境为 96 vCPU、512GB 内存、1TB 块存储,操作系统为 CentOS 7.5。结果显示,在大规模场景下,金仓时序数据库优势明显。
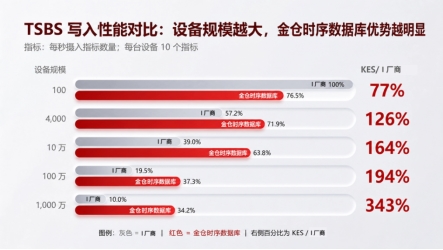
这组数据的重点,不是简单证明某个产品“更快”,而是说明金仓时序数据库的优势主要在大规模、高基数、持续写入场景中释放。对轨道交通、能源电网、工业现场这类系统来说,设备数量和采集点数量通常只会增加,很少会减少。
写入只是起点 复杂查询才接近真实业务
时序数据写入之后,真正的业务问题才开始出现。系统要查某个测点一天的曲线,也要查某个时刻所有测点的断面;要做阈值筛选,也要做趋势聚合;在交通和能源场景里,还经常要把时间、空间、设备、区域和业务状态一起放进查询条件。
这也是为什么时序数据库不能只看写入吞吐。在模拟 benchANT 官网公开测试场景中,金仓时序数据库在读写吞吐上都表现出明显优势。
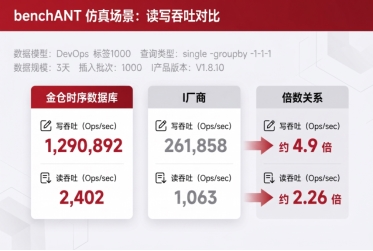
更能拉开差距的是复杂查询。简单查询场景下,金仓时序数据库与I厂商表现基本相当;进入跨时间窗口、跨设备维度、阈值过滤、最新位置和高负载识别等复杂查询后,金仓时序数据库的优势开始放大。
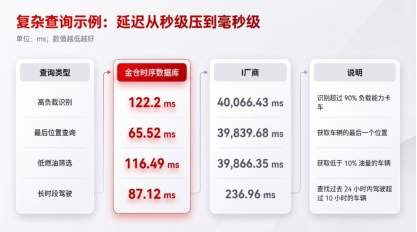
这里的核心并不是单个数字有多漂亮,而是复杂查询更接近生产系统。真实业务很少只问“某个点在某个时间是多少”,更多是在问“哪些设备正在异常,异常是否和位置、状态、工单、历史曲线有关”。
为什么不是普通分区表就够了?
很多企业在处理时序数据时,会先想到用普通关系表按时间分区。这条路可以解决一部分问题,但数据规模上来之后,普通分区表在压缩、排序、IO 控制和时间窗口查询上会遇到瓶颈。
同等表结构和数据量前提下,时序表在插入、曲线查询、断面查询、统计查询上都明显优于普通分区表。原因并不神秘:时序表可以围绕时间列、采集点和排序规则做专门组织,压缩时指定压缩列和排序列,减少IO,再配合专门的执行框架提升查询效率。
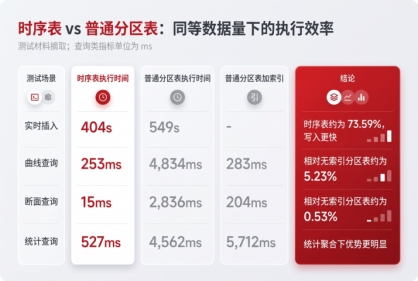
所以,金仓时序数据库的价值不是在关系库旁边再放一个“时序插件”。它解决的是时间数据在大规模写入、压缩存储、窗口查询和聚合分析中的专门优化问题。
从时序能力到融合分析关键是把上下文接进来
时序数据很少单独产生业务结论。一条温度曲线,要结合设备台账和维修记录判断风险;一段车辆轨迹,要叠加地理围栏和道路区域判断是否异常;一组电网负荷波动,要关联用户档案、区域模型和历史曲线,才能辅助调度。
这就是金仓时序数据库需要放在 KES V9 融合数据库架构下理解的原因。时序模型不是一个孤立的专用库,而是与关系、GIS、文档、向量等模型共同进入统一数据底座。

在这种架构下,企业不必为时序数据、空间数据、业务数据和向量数据分别建设多套系统,再通过复杂链路做同步和拼接。数据可以在统一平台内完成采集、存储、压缩、查询、空间计算、关联分析和智能检索。少一次搬运,就少一次延迟;少一套系统,就少一层治理复杂度。
分布式架构解决的是“海量数据怎么承载”,融合架构解决的是“时间数据怎么进入业务分析”。前者决定系统能不能撑住规模,后者决定数据能不能产生价值。
行业落地:从监控指标进入核心业务链路
时序数据库的价值,最后还是要回到生产系统。金仓时序数据库承载的不是单纯的指标入库,而是高频写入、实时查询、空间分析和综合研判共同组成的业务链路。
例如在北京轨道交通TCC应急指挥调度平台项目中,金仓数据库通过高可用读写分离架构,主节点承载高频写入,从节点支撑实时大屏、业务查询和后台分析。优化后的数据接入层支持大批量、高吞吐的数据写入,轻松应对每秒数十万数据点的洪峰,写入性能相比旧系统提升超10倍。
不止于时序才能释放时序价值
时序数据的价值,不在于它有时间戳,而在于它能还原业务运行的连续过程。下一代时序数据库的竞争,也不会只停留在写入速度、压缩比和单点查询性能上。
写得快,是基础;查得快,是门槛;能分布式扩展,是进入海量场景的条件。更关键的是,时序数据能不能与关系、GIS、文档、向量等多模数据在同一底座内完成融合分析。
金仓时序数据库的价值正在这里:它不是再造一个孤立的专用时序库,而是把时序能力放进融合数据库体系,让时间数据从监控指标进入业务分析链路,成为可查询、可关联、可治理的一类核心数据。















