核心数据库做国产化替代、混合架构整合、多源数据汇聚——这些场景里,数据同步软件选不好,迁移成本和运维风险都会翻倍。
金仓数据库的 KFS 用无中间库直连架构做数据同步。它的思路很朴素:把传统三段式方案里的中间库拿掉,让源库直接连目标库。说起来简单,但中间的工程挑战不小。先看看传统方案到底卡在哪里。
中间库、停机窗口、异构适配——三座大山
传统数据同步方案最让人头疼的问题有三个,而且这三个问题是互相放大的。
第一是停机窗口不可控。传统方案要求在业务低峰期做全量同步,但增量同步又容易因网络抖动或事务冲突而中断。中断一次,停机窗口就得重新规划,这在金融核心系统、医疗 HIS 系统这类 7×24 小时运转的场景里几乎不可接受。
第二是中间库又贵又复杂。市面上多数同步软件用的是三段式架构——源库先写到中间库,中间库做缓存和转换,再写到目标库。这个设计在早期是合理的,因为当时异构数据之间的转换确实需要一个中间层。但问题是,中间库本身需要额外的硬件成本,而且多了一段复制链路,数据一致性校验也跟着变复杂。到了大规模同步场景,中间库往往第一个成为性能瓶颈。
第三是异构源适配成本高。一个企业的 IT 环境里,Oracle、MySQL、SQL Server、PostgreSQL 经常共存,甚至还有文件、日志这类非标数据源。每加一种源端,同步软件就得做额外的适配开发,周期拉长不说,运维团队要掌握的知识面也跟着扩大。
这三个问题叠加在一起,让数据同步从"技术选型"变成了"项目风险"。金仓数据库的KFS 要解决的就是这个。
源库直连目标库,链路能短到什么程度
KFS 的方案说起来不复杂,做起来不容易:去掉中间库,源库直接连目标库。
这个架构意味着数据从源库出来之后,经过 KFS 同步引擎的日志解析、过滤和分片并行处理,直接写入目标库。中间不经过任何中转节点,数据链路被压缩到了最短。
但这只是结构层面的变化。真正让这个架构能跑起来的是底层的日志级捕获技术。传统方案用的是定时轮询,每隔一段时间去源库查一下有没有新数据,这种方式的延迟是分钟级的,而且轮询本身也会给源库带来额外的查询负载。KFS 的做法是直接解析源库的事务日志(Oracle 的 Redo Log、MySQL 的 Binlog、SQL Server 的事务日志、PostgreSQL 的 WAL),在数据变更发生的瞬间就捕获到,延迟控制在亚秒级。
除此之外,KFS 在同步引擎层面做了行级和列级的精准过滤,只传需要同步的数据,减少无效传输。多通道分片并行则确保带宽和目标库的写入能力被充分利用。

4.5TB 日增量压测,跑出了什么结果
架构设计得再好,最终还是用数据说话。金仓做了一次极限压力测试,参数如下:
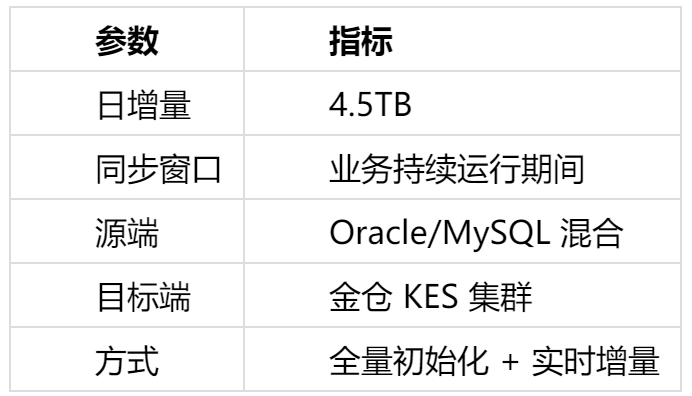
在这个量级的压力下,KFS 全量同步在预定窗口内完成,没有发生数据丢失;增量同步延迟保持在亚秒级,业务端几乎感觉不到;通过实时在线校验,源端和目标端数据保持 100% 一致;全程无中断、无回退,引擎运行稳定。
4.5TB 这个数字放在传统同步方案里,往往需要专门的硬件规划和多轮调优才能勉强应付。KFS 能扛住,靠的就是前面说的两件事,无中间库架构把链路压缩到最短,日志级捕获把延迟压到最低。
SQL Server 的 GO 命令,MySQL 的 Binlog,怎么处理
异构同步不只是"把数据搬过去",不同数据库有各自的特性,处理不好就是数据不一致的隐患。
SQL Server 这边,KFS 需要处理几个特殊的机制:
事务边界的保留,SQL Server 的三种事务模式(自动提交、显式、隐式)在同步时不能混掉;
GO 命令的解析,这不是标准 SQL,但 SSMS 的用户大量使用;
IDENTITY 自增列的逻辑,同步过去之后自增序列要一致;
全局临时表和本地临时表的处理,这些表的结构和数据的生命周期跟普通表不一样。
MySQL 这边,KFS 支持 5.x 和 8.x 全版本协议,不需要修改源端配置。DDL 表结构变更实时同步到目标端,BLOB 和 TEXT 类型的大对象做分块同步。这些细节处理好了,异构同步才不会在关键时刻掉链子。
中国石化的账本,同步后效率提了 60%
技术能力最终还是要在真实业务里验证。
中国石化财务共享系统覆盖应收、应付、总账、薪酬等核心财务模块,与费用报销、司库管理、增值税管控深度集成。这套系统每天要处理海量的财务数据,对数据一致性和同步稳定性要求极高。电科金仓和石化盈科组成的联合项目团队采用了标准的 KFS 迁移方案:先用 KDTS 完成历史数据批量迁移,再用 KFS 实时捕获原库日志做增量同步,同步过程中持续进行在线校验,最后在业务低峰期完成最终切换。
整个过程财务系统没有停过,升级完成后效率提升了 60%。对于中国石化这种体量的企业来说,财务系统效率提升 60%,意味着月底结账的周期大幅缩短,年终审计的数据准备也有了更可靠的基座。
数据同步软件的选型,最终回到一个朴素的问题:数据从 A 到 B,链路越短越好。
中间库方案在早期确实解决了异构数据转换的问题,但随着日志解析技术的成熟,直连方案在性能和一致性上的优势越来越明显。不是中间库方案错了,而是技术条件变了,当你可以直接从日志里捕获数据变更时,再多加一层中转,就成了不必要的代价。
金仓 KFS 的无中间库架构不是对传统方案的简单替代,而是基于日志级捕获技术的一次架构升级。对于正在做数据迁移的企业来说,少一个中间环节,就多一份确定性。















