在量子计算和高性能计算的交汇领域,量子张量网络方法以其强大的多体系统建模能力,成为理解复杂量子物理现象的重要工具。然而,随着系统规模与纠缠自由度的增加,张量网络算法的计算复杂度呈指数级增长,成为性能提升的关键瓶颈。针对这一行业痛点,微云全息提出了一种创新的硬件加速技术,将量子张量网络算法转换为可在现场可编程门阵列(FPGA)上运行的并行计算电路,实现了在经典硬件上的高效量子自旋模型模拟。这一成果为量子物理研究、量子算法验证以及未来量子设备的数字孪生仿真提供了全新的工程化路径。
在量子多体系统研究中,张量网络(Tensor Network, TN)算法是一种极为高效的数值工具。它通过将高维量子态分解为多个低维张量的网络结构,从而在一定程度上克服了指数级态空间膨胀问题。典型的张量网络模型包括矩阵积态(MPS)、投影纠缠对态(PEPS)以及多尺度纠缠重正化(MERA)等。这些算法在凝聚态物理、量子相变、量子自旋模型模拟等方面发挥了基础性作用。
然而,当我们希望提高系统刻画精度、引入更高纠缠自由度时,张量的维度与连通性急剧增长,使得计算复杂度从多项式级迅速跨越到指数级。以二维自旋系统为例,当纠缠秩从χ=8扩展至χ=32时,单次迭代的浮点运算量会增长近百倍,而存储带宽与访存延迟成为瓶颈。这种指数爆炸的特性使得即便是高端CPU与GPU平台,也难以在合理时间内完成模拟任务。
为此,微云全息尝试跳出传统处理器架构的限制,探索在硬件层面进行算法重构与逻辑映射的可行路径。现场可编程门阵列(FPGA)以其可重构性、并行性与低延迟特性,为张量网络计算提供了新的可能。通过将核心运算模块(如张量收缩、张量展开、矩阵乘加运算等)在逻辑层面直接映射为硬件电路,可以极大减少访存消耗和控制开销,实现深度流水线化的高密度并行计算。
微云全息该技术核心在于算法—硬件协同设计,即将张量网络算法从软件逻辑层面剖析为可直接硬件化的运算单元,并以FPGA为载体构建高密度并行的可扩展架构。
首先,对量子自旋模型的张量网络结构进行了系统分析。以Heisenberg自旋链和二维Ising模型为代表的典型系统,其哈密顿量可分解为局部相互作用项,通过张量网络编码为若干局域张量。每个张量节点的收缩本质上对应于张量乘积、矩阵乘法与求和操作。传统的CPU计算依赖通用指令集顺序执行,而GPU虽然具备大规模并行性,但受限于访存延迟和内核调度,难以实现针对性优化。FPGA架构则允许在硬件层面直接定义这些运算逻辑,消除冗余调度环节,使数据在片上高速缓存中以流水线方式连续流动。
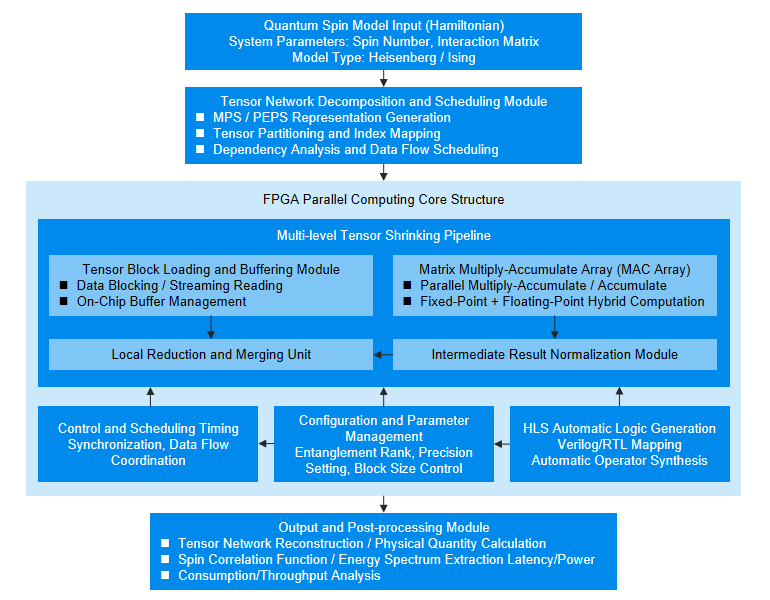
在实现上,微云全息构建了一个多级张量收缩管线(Hierarchical Tensor Contraction Pipeline)。该管线包含三个主要层次:
输入与调度层:负责将高维张量拆解为若干可处理的块结构,并进行数据流调度与依赖分析。
核心计算层:由多个矩阵乘加单元(MAC Array)构成,支持任意维度的张量收缩操作。每个计算单元均采用定制化逻辑,实现浮点加法与乘法的流水线级并行。
输出与归约层:执行张量结果的合并、归一化与中间状态缓存,为后续迭代提供输入。
在硬件逻辑设计上,通过Verilog与高层次综合(HLS)工具相结合的方式,自动生成张量运算电路,并对不同张量连通图采用多重分区策略。通过静态调度与数据复用机制,计算单元在片上形成高密度并行阵列,实现了在有限逻辑资源下的最大计算吞吐率。
在FPGA上实现张量网络算法的关键挑战在于:如何平衡并行度、访存带宽与逻辑资源消耗。微云全息通过一系列创新设计解决了这些核心难题。
首先,微云全息提出了动态张量块分割机制。在传统张量收缩中,整个高维张量往往被整体加载至主存中进行批量计算,而这在FPGA架构中会造成严重的存储瓶颈。为此,用分块分区策略,将张量分解为若干子块,并通过片上缓存(On-Chip Buffer)和外部DDR存储的交错访问,实现流式计算。通过调度控制器的优化,数据在多个MAC阵列之间高效传输,从而避免了频繁的外部访存操作。
其次,微云全息开发了一套自适应并行算子生成器。该生成器依据张量维度与纠缠秩自动生成逻辑阵列规模与连接拓扑,从而使FPGA能够针对不同的量子模型(如自旋1/2链、二维晶格或随机相互作用模型)自动调整并行度与资源占用。这种可扩展设计确保了算法可在不同规模FPGA芯片上高效部署。
第三,微云全息引入了定点化与混合精度计算策略。传统的浮点计算虽然精度高,但在FPGA上占用大量逻辑单元。通过在张量收缩中使用混合定点格式(如16位定点加24位浮点)替代全精度浮点运算,在不显著损失精度的情况下,获得了高达1.5倍的计算吞吐率提升。
此外,微云全息设计了多级流水线控制机制,使计算单元在张量加载、运算与结果写回的不同阶段并行执行。整个加速器在逻辑时钟周期内实现了持续的数据流动,使FPGA的计算单元利用率超过90%。
微云全息该技术的意义不仅在于提升计算性能,更在于探索一种新的量子算法—硬件协同演化模式。通过将量子张量网络算法的计算结构直接映射到FPGA逻辑电路中,展示了量子物理研究与可重构计算技术的深度融合。
该技术以FPGA为核心硬件平台,提出并实现了一种用于加速量子张量网络计算的并行化硬件架构。通过算法结构重构、逻辑电路映射、流水线化设计与混合精度优化,微云全息成功地将复杂的张量网络计算任务转化为高效的FPGA逻辑运算,实现了比CPU快1.7倍、能效提升2倍以上的性能突破。该技术不仅展示了FPGA在量子模拟中的潜力,也为量子算法硬件化、可重构量子加速器设计提供了实践依据。
未来,微云全息将继续沿着算法到电路的设计理念,推动更多量子计算核心模块的硬件实现,包括量子变分算法(VQE)、量子线性系统求解器(QLSA)以及量子机器学习模型的FPGA化,以构建完整的量子算法加速生态。相信,通过这一方向的持续研究,FPGA将成为量子计算与经典计算之间的重要桥梁,为量子科技产业化发展提供坚实的技术支撑。















