近日,华瑞指数云ExponTech CTO曹羽中受邀出席在英伟达全球总部举办的AI Storage技术研讨会,并发表主题演讲, 在演讲中首次公开了华瑞指数云自研的AI原生分布式KV Cache存储系统WQS面向KV Cache的IO Pattern进行原生设计和优化的架构设计思路。WQS依托三大核心技术创新、与英伟达CMX架构的深度生态契合,在解决AI推理的内存墙问题上实现了新的突破,为业界带来了AI上下文存储层的全新解决方案,充分彰显了华瑞指数云在AI基础设施领域的技术积淀与创新实力。

当前,人工智能发展正式迈入Agent AI时代,大模型从单一的问答交互向多步骤、多轮次的智能体工作流演进,法律、科研、代码开发等行业的生产级应用,对大模型推理的上下文长度提出了极高要求,128K、512K乃至百万Token级别的长上下文,已成为当下生产环境的实际需求。作为承载大模型推理上下文的核心数据结构,KV Cache不再是简单的性能优化项,而是成为AI应用的“工作内存”,单次对话产生的KV存储体量就可达数百GB,不仅需要跨轮次持久化、跨节点共享,更要具备极致的访问速度,避免让GPU陷入等待。 然而,传统存储方案却难以适配Agent AI时代的KV Cache需求:
仅依靠GPU HBM存储受限于物理容量,面对高并发长上下文场景极易耗尽
扩展至系统DRAM虽提升了容量,但是提升的容量仍然有限,并且成本高昂且无法实现真正的跨节点共享
基于分布式文件系统的外置存储方案则存在结构性IO模式不匹配,对KV Cache的小型随机IO处理效率低下等问题,导致被迫采用很大的chunk进行大块读写,降低了缓存命中率,同时导致了比较大的时延开销
在此背景下,华瑞指数云WQS系统从底层架构出发,完全按照AI推理的实际运行逻辑和IO特征设计,成为一款真正适配Agent AI时代的AI原生分布式KV Cache存储产品。
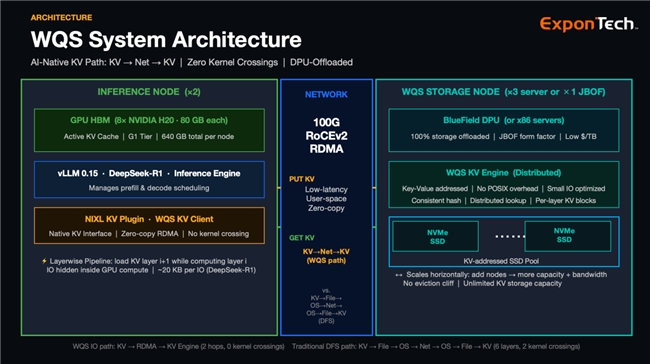
华瑞指数云WQS是一款以“解决KV Cache内存墙问题”为核心的分布式KV存储系统,核心定位为AI推理场景的专用上下文存储层,精准契合英伟达 CMX 架构对 G3.5 层的技术定位与能力要求,可直接作为GPU HBM的透明延伸,实现KV Cache的高效、弹性、低成本存储与管理。不同于传统存储方案对通用架构的适配改造,WQS从设计之初就深度贴合KV Cache的技术特性,构建了AI原生KV接口与KV Engine、Layerwise流水线加载、DPU原生架构三大协同工作的技术支柱,从数据访问和IO处理模式、加载逻辑、硬件部署三个维度,彻底解决传统方案的结构性痛点,打造出适配KV Cache小型随机IO特性的全链路优化体系。

创新一:AI原生KV接口与KV Engine,彻底消除文件系统冗余开销
WQS打造的AI原生KV接口与分布式KV Engine,是其适配KV Cache访问特性的核心基础,从数据处理和传输路径上彻底摒弃了传统文件系统的弊端。不同于传统分布式文件系统需要经过KV到文件协议的转换翻译、内核调用、元数据访问等8层复杂路径,WQS完全消除了文件系统抽象,摒弃POSIX接口与文件、目录命名空间,采用与推理引擎追踪GPU HBM中KV块完全一致的Block ID直接寻址,让外部存储成为GPU HBM的透明延伸,从根源上避免了KV Cache与文件系统的结构性IO模式不匹配。
同时,WQS构建了专为小型随机IO设计的分布式KV Engine,内部通过一致性哈希实现块放置、分布式查找和逐层块寻址,不依赖于通用存储系统的任何既有能力;数据传输全程基于RDMA实现全用户态、零拷贝传输,无需内核介入,彻底消除了系统调用、内核上下文切换带来的开销,将使用传统分布式文件系统的8层IO路径简化为“AI框架-KV Engine-NVMe SSD”的2跳直连路径。这一设计让WQS即便在16KB-64KB的KV Cache典型小型IO场景下,也能保持稳定的高带宽性能,彻底摆脱了传统分布式文件系统在随机小IO场景下带宽断崖式下跌的问题,为生产环境中的极致性能奠定了路径基础。
WQS 的原生KV能力甚至带来了KV Cache上下文管理的设计哲学的根本转变:当使用分布式文件系统作为KV Cache后端时,每次 IO 都很昂贵,因此整个系统的设计哲学是:最小化 IO 次数,保证高带宽。这意味着被迫使用大 chunk——256 个 Token,让每次 IO 携带 10MB 或更多数据,这样才能满足KV Cache要求的高存储带宽的需求;而基于 WQS 的原生KV能力,存储系统在小IO时的带宽不再是瓶颈,设计哲学变成了:达到更高的缓存命中率,实现更低的时延,你可以使用 16-Tokens 的 chunk——比之前细 16 倍的粒度,同时还可以使用 Layerwise 流水线加载,在计算过程中异步加载KV,单次IO的尺寸进一步切分为原来的1/N (N为模型的层数),时延达到最低并且完全隐藏于计算过程中,同时依然可以达到接近物理网络上限的存储带宽。
创新二:Layerwise流水线加载,将IO延迟完全隐藏于GPU计算时间
针对Transformer模型逐层顺序计算的核心运行特性,WQS基于其对随机小IO的优化设计,完美应用了Layerwise流水线加载技术,实现了KV Cache IO操作与GPU计算的完全重叠,从加载逻辑上最大化压缩整体处理时间。传统KV Cache加载方式需在计算开始前一次性加载整个会话的KV快照,总耗时为KV Cache数据加载时间与计算时间之和,而WQS则利用模型逐层计算的时间窗口,在GPU计算第i层KV数据的同时,异步从存储中预取第i+1层的KV块,当GPU完成当前层计算、准备进入下一层时,对应的KV数据已提前加载完毕,让IO延迟被完全隐藏在GPU计算时间内,系统总耗时趋近于GPU纯计算时间。
这一技术不仅实现了延迟的大幅优化,更形成了与WQS AI原生KV架构的协同优势:若模型有60层,由16个tokens组成的一个KV block的单次大IO将被拆解为60次约20KB~64KB的小IO,而这一尺寸恰好落在WQS的性能优势区间,既能高效饱和RDMA网络带宽,又能达到极致的低时延和分层的流水线加载。目前,WQS已与vLLM深度集成,通过`maybe_transfer_kv_layer`专属钩子函数实现流水线加载的自动化调度,在计算前等待加载完成、计算后异步保存更新的KV,让推理引擎与存储系统紧密协同,无需对推理引擎大幅改造即可快速落地,在真实生产部署中有效转化为端到端延迟的极致优化。
创新三:DPU原生架构,实现存储处理全卸载与硬件极致提效
WQS的DPU原生架构,从硬件部署层面实现了存储处理与推理计算的资源分离,让主机计算资源最大化服务于大模型推理,同时实现存储层的高密度、低成本、线性扩展。WQS可以将100%的软件栈全量迁移至BlueField DPU运行,把网络终结、IO调度、元数据管理、数据放置等所有存储处理工作,全部卸载到这款专为网络附加存储设计的ARM处理器上,实现主机CPU的零参与,让推理节点的CPU、GPU资源可全部投入到大模型推理计算中,从资源分配上提升推理效率。
在硬件形态上,WQS采用JBOF纯闪存机箱设计,单台WQS存储节点可搭载3~6块BlueField-3 DPU、26块NVMe SSD, 提供Tbps级的网络带宽,无需昂贵的专用存储服务器硬件,实现了更高的硬件密度与更低的功耗。实测数据显示,单台WQS存储节点的等效性能堪比三台传统存储服务器,大幅降低了单位存储容量的硬件成本;同时,WQS存储层采用分布式集群设计,所有节点通过KV寻址构成统一的SSD池,支持水平线性扩展,增加节点即可同步提升存储容量和带宽,不存在传统DRAM、HBM方案的容量天花板,也无“KV数据发生驱逐时导致的性能悬崖”问题,在真实客户高并发、长上下文的生产部署中,始终能保持稳定的性能输出,成为吞吐量提升22倍的重要硬件支撑。
依托三大核心技术创新的协同发力,WQS还实现了CacheBlend非前缀缓存复用能力的全面释放,进一步放大了生产部署中的性能优势。WQS凭借极低的单IO成本,将缓存匹配粒度从传统方案的256-Token大幅缩减至16-Token,结合CacheBlend技术可在序列任意位置匹配复用KV块,打破了传统前缀缓存“一处不匹配即全部失效”的局限,即便是非前缀位置的重复内容,也能实现高效复用。这种细粒度的缓存设计,让跨轮次、跨用户、跨会话的KV Cache复用成为现实,将缓存优化的核心目标聚焦于缓存命中率最大化,在真实生产环境中持续提升缓存命中率,进一步减少GPU冗余计算。
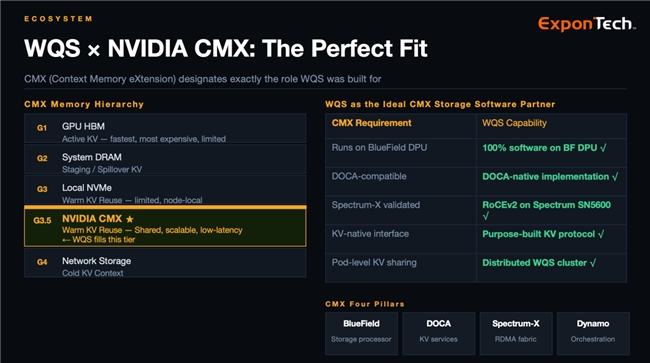
值得一提的是,WQS与英伟达最新推出的CMX(Context Memory eXtension)上下文内存扩展架构实现了完美契合,是英伟达CMX架构的理想软件合作伙伴。CMX架构在内存层级中正式定义了G3.5层,专为热/温KV复用设计,而这正是WQS的核心应用场景。WQS全面满足CMX架构的所有技术要求:100%运行在BlueField DPU上、支持DOCA原生开发、基于Spectrum-X验证的RoCEv2 RDMA网络、提供KV原生接口、支持跨节点的Pod级KV共享,双方从硬件生态和软件协议两个维度,共同完善了AI推理的内存层级体系,为大模型长上下文推理提供了一体化的基础设施解决方案。 经过生产级硬件的多轮验证,WQS已展现出优异的性能表现,在对接真实企业生产环境的A/B测试中,面对30-100并发用户的长上下文Agent工作负载,可实现首Token延迟的5倍加速和4.7~5倍的吞吐量提升,有效消除了仅使用HBM和DRAM作为KV Cache时的容量局限性和性能悬崖。在商业价值层面,WQS不仅能将GPU的有效计算占比提升至90%以上,消除50%-90%的冗余GPU计算成本,让企业的GPU投资实现最大化利用;更重要的是,其解锁了百万Token持久对话、多会话AI智能体、跨长周期的上下文持久化等此前难以实现的应用场景,为法律AI、研究AI、代码AI等生产级大模型应用的落地奠定了坚实的存储基础。
此次亮相在英伟达总部举办的AI Storage技术沙龙,华瑞指数云WQS系统的创新设计、成熟的落地能力和显著的性能优势,获得了行业各界的高度关注与认可。作为深耕AI基础设施领域的技术企业,华瑞指数云始终聚焦大模型推理场景的基础设施痛点,以技术创新为核心,打造适配Agent AI时代的专属产品与解决方案。未来,华瑞指数云将持续深化与英伟达的生态合作,以WQS为核心抓手,不断优化AI原生分布式KV Cache存储技术,同时围绕大模型推理的全链路需求,打造更多硬核产品与解决方案,助力企业突破AI规模化推理的存储瓶颈,加速大模型技术在各行业的深度落地与价值释放,为AI产业的高质量发展注入新动能。在生产落地层面,华瑞指数云已经与深圳大普微进行战略合作,联合推出针对KV Cache和推理上下文的一体化存储产品:“岳磐”推理存储一体机,目前岳磐一体机已经在多家企业级客户的AI推理生产集群实现落地,在2026年将实现在大量的企业级AI推理场景落地。















