最近一段时间,“Agent自动运维”这个话题在数据库圈越来越热。OpenClaw也好,各种基于大模型的运维Agent也好,能力确实不一般——给它一段日志,能分析出问题根因;给它一个告警,能自动生成处理方案;某些场景下,整个诊断—决策—执行的闭环,DBA根本不用介入。
这不是噱头。这类工具的分析速度和覆盖广度,比人工处理快太多了。
但有一个问题:这些Agent,到底应该被允许触碰数据库到什么程度?
Agent很强,但它不是原生的
这类工具有一个共同特点:开放、通用。正因为通用,才能跨数据库品牌、跨运维场景。但也因为通用,它对任何一个具体数据库的理解,始终是“外部观察者”的视角。
数据库内核的状态信息是很精细的——事务号、缓冲区脏页、锁等待链、慢SQL执行计划、会话历史采样……这些数据只有真正理解这个数据库的工具,才能准确获取、准确分析、准确执行。
更根本的是安全性问题。数据库是企业数字化最核心的基础设施,内核数据的访问权限肯定不可随便开放。AI分析能力再强也无法直接对接数据库内核,因为这不是一个可控的信任边界。
缺的不是Agent,而是中间那一层
未来智能运维架构,或许不是“Agent直连数据库”,而是这样一个结构:
“数据库—专业管控平台—Agent”三层,由专业管控平台来控制边界。
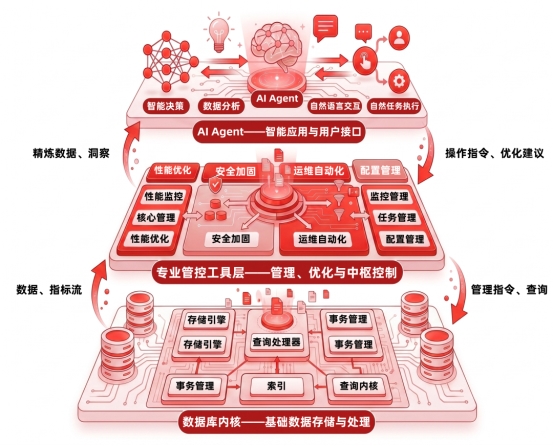
其中专业管理工具层在这里扮演者不可或缺的角色。
一、它要足够深。能拿到内核级的精准数据,不是表面指标,而是那些只有原生工具才能获取的信息。要集成数据库引擎内置的诊断能力,能主动发现问题、分析问题,而不是靠Agent在外面猜。
二、它要足够安全。能在不暴露内核的前提下,把结构化的、可信的信息传递给上层。知道哪些操作能做、怎么做,是执行链路上的最后一道门。
三、它要足够准。数据精度是整个链路的基础。Agent的判断建立在数据之上,数据模糊或滞后,Agent再聪明也会出错。
既然这层这么重要,为什么不直接把Agent能力内嵌进管控工具?不是更简单?成本更低?
这其实是两种不同演进路径。内嵌的问题在于把AI的快速迭代和管控工具的稳定性绑死了。大模型迭代速度快,每次升级都要重新集成、测试、发版,和管控功能迭代互相牵扯。在演进节奏、知识深度、系统复杂度三个方向都会引入不确定性,最终可能会影响到数据库本身的安全。同时,通用模型不懂KES内核,硬塞进去上限就是个外行模型。再加上管控加训推两套复杂度叠在一起,维护、排障、审计的难度都上去了。外置让Agent独立迭代,还能统一调度多套工具、覆盖多种数据库,系统更合理,更新成本更低。
KEMCC在这个架构里是什么位置?
金仓企业级统一管控平台KEMCC,是金仓数据库生态的集中管控中枢,也是20余年数据库工程积累的落地成果。
这里有个关键点:KEMCC对KES内部架构的理解深度,是任何第三方工具无法复制的。这种耦合程度不是宣传语,而是结构性的、系统性的——KES本身的能力。
这个“原生”具体体现在哪里?
1.数据粒度方面
KEMCC支持分钟级乃至秒级的指标采集。采集的不只是CPU、内存这类操作系统层面的数据,而是数据库层面的:事务号、缓冲区命中率、索引扫描统计、长事务持续时间、慢SQL抖动情况……这些指标如果从外部探针去采,要么根本采不到,要么精度差很多。
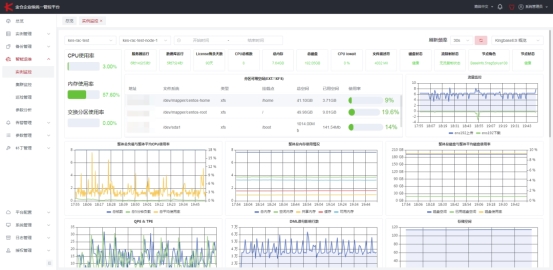
KEMCC监控大盘界面
2.诊断深度方面
KEMCC集成了数据库引擎内置的诊断工具,能持续监控实例、自动识别潜在问题,向用户提供诊断信息和改进建议。这不是"喂日志给大模型"的路子,而是基于原生引擎视角的主动分析——它本身就具备自动发现问题、分析问题的能力,不需要外部Agent来补这部分工作。
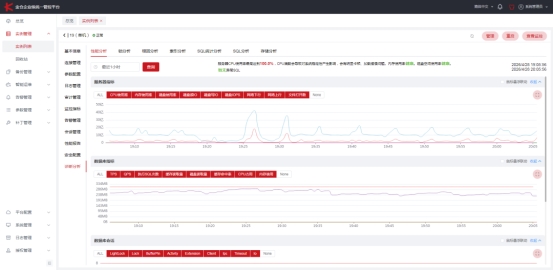
KEMCC诊断分析界面
3.执行可信方面
当上层做出判断后,最终执行的动作必须由“知道怎么做才对”的工具来完成。KEMCC提供了从容量扩展、实例规格变更到补丁管理的完整执行能力,每一步都有操作日志,可审计、可回溯。
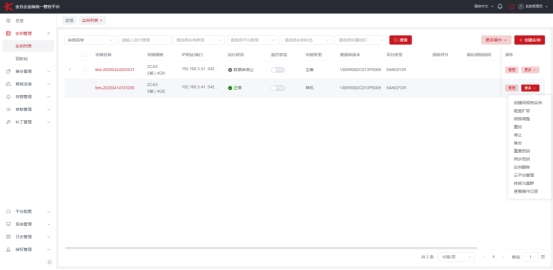
KEMCC操作管理界面
4.安全隔离方面
KEMCC支持SSL加密传输、国密算法,以及透明加密等数据保护机制,满足网络访问有严格限制的企业环境——即便接入更上层的智能系统,访问边界也是受控的。
KEMCC安全管理界面
一部分工作,可以不用手搓了
KEMCC目前能做的事,放在几年前,是需要用户盯着屏幕逐项排查的:
实时监控性能指标,通过邮件、短信、微信等渠道推送告警,不用守着控制台也能第一时间知道;
自动分析SQL执行情况,识别优化空间,推荐合适的索引策略,量化收益预测;
SQL分析与优化建议界面
定期扫描数据库健康状况,自动评分,异常项主动预警,提前发现风险;
备份策略按计划自动执行,备份集自动检测,出问题自动报告。
这些能力,已经在把相当一部分重复性的运维工作从解放出来。
再往前走一步,当管控平台开放标准接口、与上层AI Agent协同时,整个链路才算真正打通:Agent负责判断“做什么”,KEMCC负责“怎么做”和“做完之后状态如何”。分工清晰,边界明确。
为什么这一层省不掉?
那Agent发展这么快,以后会不会直接绕过管控层?
至少在生产环境里,这条路尚且还走不通。
数据可信性。内核级诊断数据只有原生工具能精准获取。这不是接口权限的问题,是理解深度的问题。
执行安全性。数据库操作很多时候后果不可逆,一个调参指令下去可能影响整个集群。中间有一层“知道规矩”的工具做缓冲,出错的代价会小很多。
审计合规。企业级场景下,每个操作都要有迹可查。操作日志、系统日志、数据库日志形成完整的审计链路,Agent替代不了这个。
审计日志界面
管控层自身稳定性。KEMCC支持主备高可用部署,主节点出现故障时可自动切换至备节点,保障管理服务的连续性。管控层本身稳不稳,直接决定了整套智能运维体系能不能立起来。
接下来会发生什么?
当然,现在说的这些还只是“缓冲层”的逻辑。更进一步的方向,是让这个缓冲层真正对Agent友好。
电科金仓计划发布一系列Skills,让Agent能以标准化的方式调用KEMCC的能力,不用再靠对接裸接口、自己解析数据。这个动作本身就是对“KEMCC不可或缺”最好的注解,给Agent一把更懂KES的钥匙。
AI改变运维方式,这没什么悬念,无论是厂家还是用户都要积极拥抱它。但需要认识到这种改变的方式是“分工”,不是“完全替代”。
Agent会越来越聪明,但它始终需要一个懂数据库的搭档——帮它看清内部真实状态,帮它把决策转化成安全可控的动作。各模块间也需要明确的信任边界。让业务运行更可靠、安全。
总之,越是走向自动化,对数据精度和执行安全的要求反而越高,对于数据库来说,真正稀缺的,从来不是“更聪明”,而是——始终可控的确定性。这时候,KEMCC作为专业管控平台这层的价值不是在变小,而是在变大。它不仅是更好的一只手,更是处于AI的“强未知性”与内核的“强确定性”中间的一道缓冲墙,让业务能既快又稳地运行,让“自治”真正从“可尝试”变成“可依赖”,成为长期托付的生产能力。















