近日,自然语言处理领域顶级国际学术会议 ACL 2026(第 64 届国际计算语言学协会年会)公布论文接收结果。云知声表现亮眼,共有 4 篇论文成功录用,其中 3 篇入选主会(Main Conference),1 篇入选 Findings。本届 ACL 共收到 12148 篇投稿,经多轮严格评审,主会论文接收率仅 19%,Findings 论文接收率为 18%。

ACL 作为人工智能与计算语言学领域公认的全球顶会,聚焦大语言模型、智能体、文本挖掘、对话系统等前沿方向,是全球科研成果与技术创新的权威风向标。ACL 2026 将于 7 月 2 日 —7 月 7 日在美国圣迭戈举办。
云知声此次入选的 4 篇论文,精准覆盖多模态语音识别、全模态情感识别与推理、文档理解与阅读顺序检测、强化学习四大关键赛道,直击行业共性技术痛点,提出的原创理论与算法,为全模态大模型、行业智能体的技术迭代提供了全新思路。其相关创新研究也与 UniGPT、山海・知音 2.0、U1-OCR 等模型产品形成深度技术闭环,为模型在严肃场景的规模化落地筑牢坚实学术根基。
以下为入选论文概览:
01
VAPO: End-to-end Slide-Enhanced Speech Recognition with Omni-modal Large Language Models
作者:Rui Hu, Delai Qiu, Yining Wang, Shengping Liu, Jitao Sang
研究方向:多模态语音识别
录用类型:ACL 2026, Main, Long paper
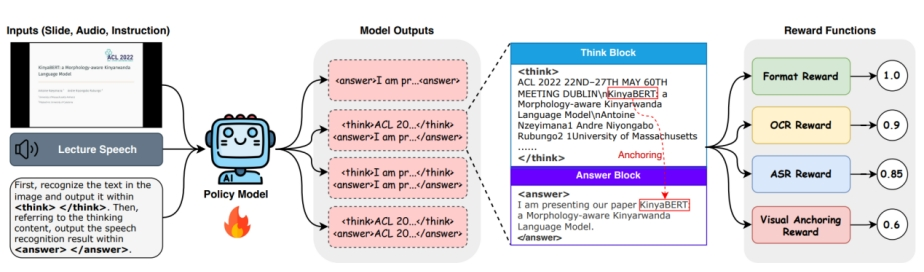
论文简介:全模态大模型在结合幻灯片视觉信息的语音识别任务中具备端到端处理潜力。然而,此类模型普遍存在视觉干扰现象,即模型过度依赖幻灯片可见文本,导致对语音内容的感知弱化,引发转录失效。
针对该问题,本文提出视觉锚定策略优化方法(VAPO),其核心在于模拟人类听取专业报告时的“先看后听”感知流程,通过思维链格式,将视觉感知与语音转录在时序上解耦:首先提取幻灯片文本作为视觉语义先验,随后以视觉先验作为锚点辅助完成语音识别。本文设计了涵盖格式、OCR、ASR、视觉锚定四类奖励函数引导模型的学习。同时,为解决现有数据专业实体密度低的问题,构建了包含合成数据集与真实数据的SlideASR-Bench基准。实验结果表明,VAPO能够有效消除全模态大模型的视觉干扰问题,在 SlideASR-Bench 及 SlideSpeech 等数据集上刷新了 SOTA 性能,并显著降低了领域专业实体的识别错误率。
02
Beyond Modality Collapse: Taming Guided Modality Entropy for Omni-modal Emotion Reasoning
作者:Xian Zhao, Rui Hu, Yuxiang Zhang, Delai Qiu, Yining Wang, Shengping Liu, Jian Yu, Jitao Sang
研究方向:全模态情感识别与推理
录用类型:ACL 2026, Findings, Long paper
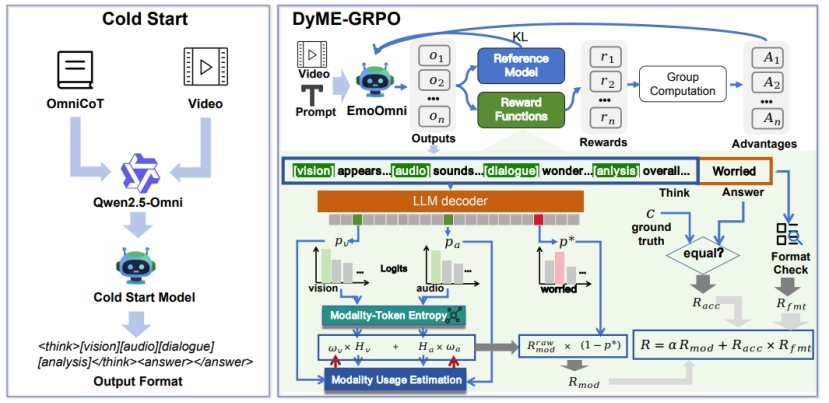
论文简介:在以人为本的人工智能领域,全模态情感识别与推理是实现深度人机交互的核心挑战。尽管全模态大模型(OLLMs)取得了显著进展,但在处理复杂情感时仍面临“模态塌陷”困境:模型往往过度向视觉等优势模态对齐,导致音频或对话语境中的关键线索被掩盖,进而在面对微妙情感时容易产生误判。
针对这一难题,我们提出 EmoOmni 模型。该模型创新性的引入了 OmniCoT 数据构建范式,通过“引导标识符(Guided Tokens)”构建认知锚点,强制模型在时序上分步提取并整合视觉、音频与文本特征,实现逻辑严密的链式推理。此外,我们提出了 DyME-GRPO 动态模态熵优化算法,通过强化学习手段动态校准模型对不同模态的依赖度,彻底解决模态失衡问题。实验表明,EmoOmni 在多项情感基准测试中刷新了 SOTA 纪录,在保持通用交互能力的同时,实现了更深层、更鲁棒的情感洞察。
03
FocalOrder: Focal Preference Optimization for Reading Order Detection
作者: Fuyuan Liu, Dianyu Yu, He Ren, Nayu Liu, Xiaomian Kang, Delai Qiu, Fa Zhang, Genpeng Zhen, Shengping Liu, Jiaen Liang, Wei Huang, Yining Wang, Junnan Zhu
研究方向: 文档理解与阅读顺序检测
录用类型:ACL 2026, Main, Long paper
论文简介:
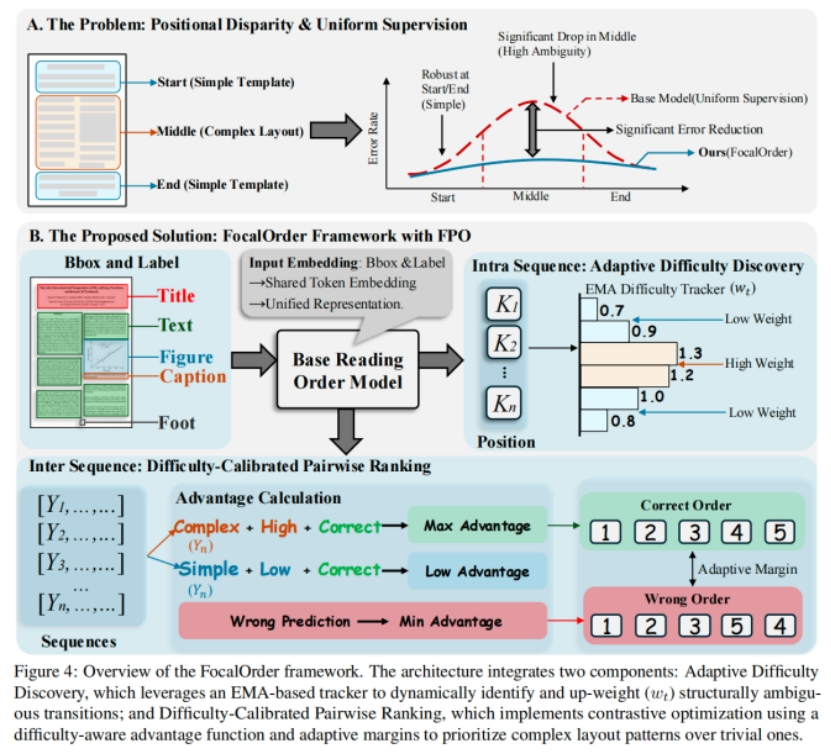
阅读顺序检测是文档理解的基础任务。现有方法大多采用统一监督方式进行训练,通常默认文档不同版面区域的学习难度分布一致。本文对这一假设提出挑战,并揭示了阅读顺序检测中的一个关键问题,即位置差异性(Positional Disparity):模型通常能够较好掌握起始和结束区域这类较为确定的布局模式,但在结构更复杂的中间区域会出现明显的性能下降。进一步研究发现,造成这一问题的主要原因在于标准训练过程中,大量简单样本的学习信号会淹没复杂布局带来的关键监督信息。
为解决上述问题,本文提出了 FocalOrder 框架,并设计了Focal Preference Optimization (FPO) 方法。具体而言,FocalOrder 通过结合指数滑动平均机制的自适应难度发现策略,动态定位难以学习的顺序转移关系;同时,引入难度校准的成对排序目标,以增强全局阅读逻辑的一致性。实验结果表明,FocalOrder 在 OmniDocBench v1.0 和 Comp-HRDoc 上均取得了新的最优性能。值得注意的是,我们的紧凑模型不仅优于多种具有竞争力的专用方法,也显著超过了大规模通用视觉语言模型。该研究表明,使优化过程与文档结构本身的内在歧义性相匹配,对于提升复杂文档结构建模能力至关重要。
04
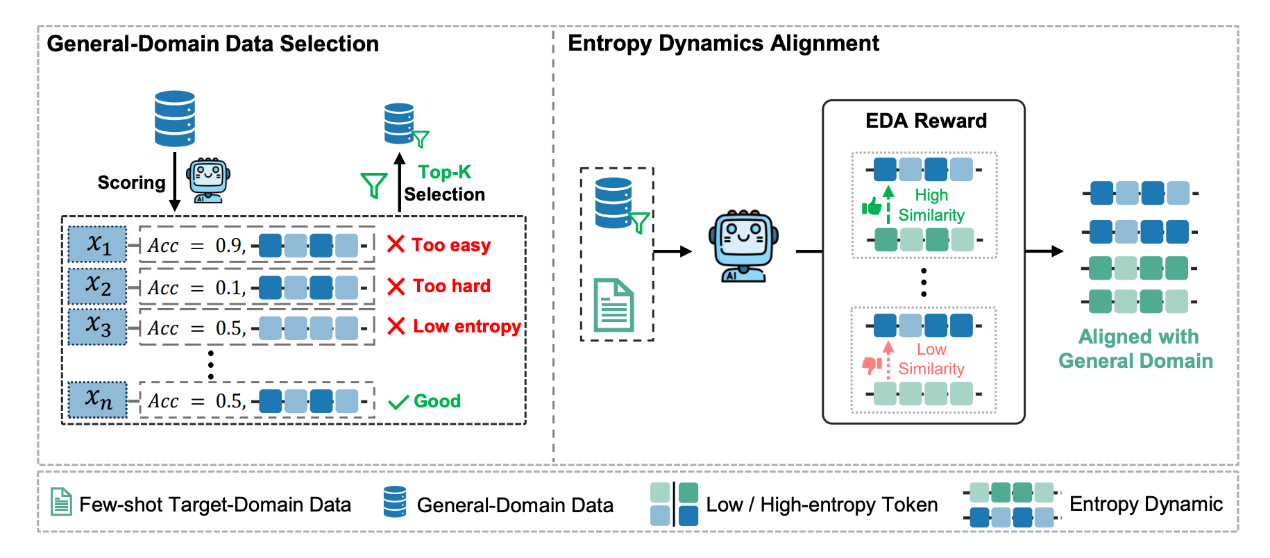
HEALing Entropy Collapse: Enhancing Exploration in Few-Shot RLVR via Hybrid-Domain Entropy Dynamics Alignment
作者:Zhanyu Liu, Qingguo Hu, Ante Wang, Chenqing Liu, Zhishang Xiang, Hui Li, Delai Qiu, Jinsong Su
研究方向:基于可验证奖励的强化学习
录用类型:ACL 2026, Main, Long paper
论文简介:基于可验证奖励的强化学习(RLVR)在训练推理导向的大语言模型方面已展现出显著成效,但现有方法大多假设资源充足、训练数据丰富。在低资源场景下,RLVR 极易遭遇更为严重的熵坍缩问题,这极大地限制了探索空间,并削弱了推理性能。
为此,我们提出混合域熵动态对齐(HEAL)框架,专为少样本 RLVR 设计。HEAL 首先有选择地融入高价值通用域数据,以促进更多样化的探索。随后,我们引入熵动态对齐(EDA)奖励机制,该机制能够对齐目标域与通用域之间的轨迹级熵动态,不仅捕捉熵的大小,还刻画其精细变化。通过这种对齐,EDA 不仅进一步缓解了熵坍缩,还鼓励策略从通用域习得更丰富的探索行为。跨多个领域的实验结果表明,HEAL 能够持续提升少样本 RLVR 的性能。值得注意的是,仅使用 32 条目标域样本,HEAL 即可达到甚至超越使用 1000 条目标域样本训练的全量 RLVR 模型水平。
云知声是一家以多模态大模型为核心底座、以行业智能体为关键抓手、以严肃场景规模化落地为鲜明特色的中国原生大模型企业,并作为港股上市公司(股票代码:09678.HK)列席我国大模型第一梯队。基于云知声UniGPT大模型矩阵,公司已构建覆盖医疗、医保、交通等多个垂直行业的模型体系,并同步布局语音、OCR、影像等多模态能力。
例如:山海医学大模型在医疗文本和医学影像双核能力上持续突破,在顶尖医学大模型评测MedBench 4.0上获得三大榜单“大满贯”;山海·知音大模型2.0是一款端到端、全双工语音大模型,同时完美支持ASR与TTS,其TTS首包延迟低于90ms,在ASR、TTS及交互能力上全面达到业界SOTA水平,支持12种方言与10种外语,能够细腻还原情感表达;U1-OCR文档智能基础大模型是一款工业级文档智能基础大模型,采用ViT+LLM先进架构,拥有30亿参数,在OmniDocBench V1.5基准测试中以95.1分的成绩夺得SOTA,开启了OCR 3.0时代,完成从“字符感知”到“文档认知”的跨越。
此次收录的论文,正是围绕上述核心模型矩阵展开的技术攻关。未来,云知声将持续深耕多模态大模型与行业智能体核心技术,以科研成果驱动技术迭代,加速医疗、医保、交通等垂直领域的智能升级,助力中国大模型技术在全球舞台持续领跑,推动人工智能从技术创新走向产业价值的深度释放。















