青云科技旗下 AI 算力云服务——基石智算CoresHub4090计算卡自上线以来,深受欢迎,需求量持续激增,经常一卡难求。为了解决高峰期资源排队的难题,基石智算正式上线 A100 20G vGPU—— 这一全新算力是基于 NVIDIA A100 40G 的切分,在保障核心算力不受影响的情况下,为用户提供更充足、更高效的算力选择。
大家可能会认为:“4090 已经很强了,为什么要用 A100 20G?显存不是还小了 4G 吗?”
其实,对于绝大多数深度学习任务而言,A100 20G vGPU 不仅是 4090 24G 的完美替代,更是在带宽、架构、稳定性等方面的“降维打击”。今天我们就从硬核参数、替代合理性、适配场景和性价比四大维度,为您详细解读。
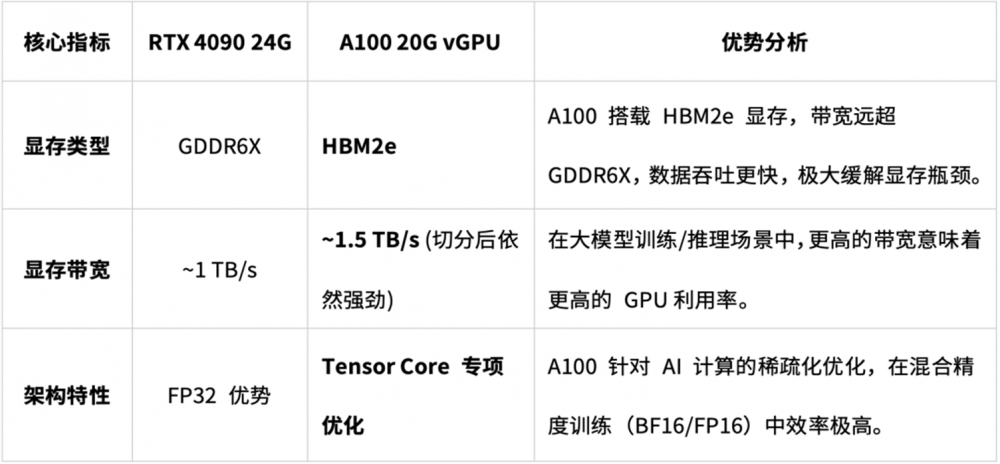
一、参数对比:数据中心旗舰卡 vs 消费级显卡
4090 是目前使用频率最高的消费级显卡,而 A100 是 NVIDIA 专为数据中心和人工智能计算设计的 Ampere 架构旗舰产品。二者在核心指标上的差异,直接决定了专业场景下的表现差距。
二、为何 A100 20G vGPU可以替代 4090 24G
1. 20G 显存:覆盖绝大多数任务,性能绰绰有余
在目前的模型训练和微调场景中,20G 显存是一个“黄金容量”。
l 微调场景:使用LoRA或QLoRA技术,20G 显存足以轻松微调 7B、13B 甚至量化后的 30B+ 参数的大模型。
l 深度学习训练:对于常见的 CV(计算机视觉)模型(如ResNet、YOLO 系列)和 NLP 模型(BERT、GPT-small/medium),20G 显存完全能够支撑较大的 Batch Size。
l 推理部署:20G 显存可以承载极高并发的模型推理服务。
2. 带宽更高:速度比容量更影响效率
很多时候显卡“卡顿”,并非显存不足,而是显存带宽不够,导致数据传输受阻。A100 20G vGPU的显存带宽比 4090 快出近 50%,意味着在训练过程中,A100 的数据加载更迅速,GPU 空转时间更少,实际训练、推理效率往往优于 4090。
3. 算力强劲:半价享整卡性能
A100 20G vGPU采用的是显存切分技术,仅限制了显存容量,而核心计算算力则完整保留。相比于租用昂贵的整张 A100 40G 物理卡,您只需支付一半的价格,就能独享 A100 完整的 Tensor Core 计算能力。对于绝大多数对显存需求适中但对计算速度要求极高的任务来说,这相当于用“亲民价”享受到了旗舰级显卡的满血算力。
三、最佳适配场景
如果您正在使用 4090 开展以下工作,强烈建议切换到 A100 20G vGPU,体验更稳定、高效的算力服务。
✅ 大模型微调 (LLM Finetuning):使用LoRA/PEFT 方法微调 Llama 3、Qwen等开源模型,A100 的稳定性和高带宽会让微调过程更丝滑。
✅ 深度学习模型训练:ResNet、ViT、Transformer 等主流模型的训练与验证。
✅ AIGC 与 Stable Diffusion:虽然 4090 单图生成极快,但 A100 在高并发、大批量图生成或训练LoRA/ControlNet 时,稳定性更佳。
✅ 学术科研与复现:长时间运行实验(数小时甚至数天)时,A100 的企业级稳定性可避免因显卡重启导致前功尽弃。
四、更低成本,更高性能
架构更先进、带宽更高、稳定性更强的 A100 20GvGPU仅需1.75 元/小时,性价比远超RTX 4090!
目前,基石智算CoresHub的A100 20G vGPU资源充足,即刻启用,告别“抢卡难”,以更低成本解锁旗舰级AI计算能力。















