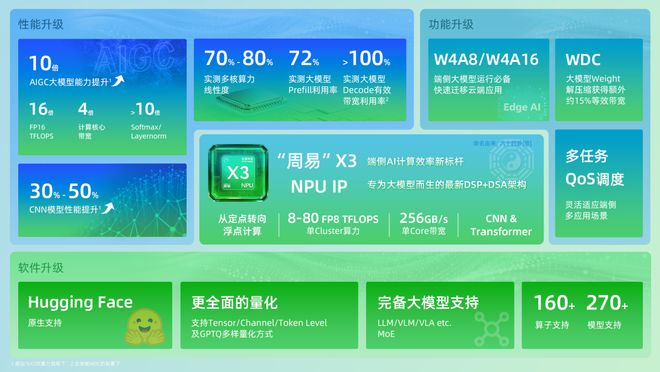
在端侧AI计算领域,一场关于精度与效率的技术革新正在悄然发生。安谋科技最新发布的“周易”X3 NPU IP通过创新的混合精度计算方案,成功破解了端侧大模型部署中的关键难题,为AI在终端设备的规模化落地提供了新的解决方案。

一、从定点到浮点:端侧AI计算的技术跨越
传统端侧NPU大多采用INT8定点计算,虽然能效比较高,但在处理复杂大模型时容易出现精度损失问题。与此不同,“周易”X3大胆转向浮点计算,创新性地采用W4A8/W4A16混合精度模式。
安谋科技产品总监鲍敏祺深入解释了这一技术选择背后的逻辑:“大模型90%的带宽消耗来自权重参数。我们采用W4低比特来有效解决存储和带宽问题,同时保留激活值的浮点精度,这是确保模型推理准确性的关键。”
二、混合精度的智慧:在矛盾中寻找最优解
“周易”X3的混合精度方案体现了精妙的技术平衡艺术。其中,“W4”将模型权重压缩至4比特,大幅减小模型体积和数据传输量;“A8/A16”则保持计算过程中的中间数据精度,确保模型推理的准确性。
这种设计带来了多重优势:首先,它消除了复杂耗时的量化过程,降低了开发门槛;其次,在保证精度的同时,显著降低了带宽需求;最重要的是,它在模型精度与系统限制之间找到了最佳平衡点。

三、全面兼容:灵活应对多样化场景
值得一提的是,“周易”X3人工智能计算平台在计算精度支持上展现出卓越的前瞻性与工程智慧,其创新性地实现了从int4到fp32的多精度融合计算能力。这一技术特性使其能够突破传统单一精度计算架构的限制,在保持高计算效率的同时兼顾了灵活性与准确性,为多样化应用场景提供了精准的算力支撑。
具体而言,在资源严格受限的智能手机边缘部署场景中,“周易”X3可通过int4/int8等低精度计算模式,在保证模型识别准确度的前提下,将功耗控制在毫瓦级别,显著延长移动设备的电池续航。而在需要更高计算精度的AI PC推理任务中,平台可智能切换至fp16或bf16精度,为复杂的图像生成、实时视频处理等应用提供强劲性能。面对智能汽车对功能安全与实时性的严苛要求,“周易”X3的fp32精度模式能够确保感知决策算法的稳定可靠,同时其多精度融合架构允许不同精度的计算任务并行处理,实现系统级能效优化。
这种全方位的技术优势使得“周易”X3不仅能够满足当前各场景下的AI计算需求,更具备了面向未来技术演进的延展性。随着大模型轻量化技术的成熟和边缘计算场景的不断拓展,“周易”X3这种兼顾性能极限与能效优化的设计理念,将为下一代智能设备的创新提供至关重要的算力基石。

四、技术突破的系统性价值
这一创新不仅体现在计算精度上,更与“周易”X3的整体架构深度契合。其单核256GB/s的高带宽为混合精度计算提供了坚实基础,而自研的WDC解压硬件则进一步提升了带宽利用效率。配合AIFF专属引擎和专用硬化调度器,整个系统在保持超高精度的同时,仍能实现低于0.5%的CPU负载。
“周易”X3的混合精度方案代表了端侧AI计算的重要发展方向。它证明,通过精妙的技术架构设计,完全可以在有限的终端资源下实现大模型的高效部署。这一突破不仅为基础设施、智能汽车、移动终端、智能物联网四大领域提供了强大的AI计算核心,更将加速边缘及端侧AI的规模化部署进程,推动端侧AI计算进入新的发展阶段。

随着AI大模型在终端设备上的应用日益广泛,“周易”X3所展现的技术路径无疑将为整个行业的发展提供重要参考。在精度与效率的平衡中寻找最优解,正是推动端侧AI持续进步的关键所在。















