2025年9月29日晚,DeepSeek-V3.2-Exp模型正式发布。优刻得模型服务平台UModelVerse极速完成接入,作为AI应用开发者,无需关注底层算力资源调度、基础环境的模型部署,UModelVerse控制台全面覆盖从模型训练到应用上线的全流程,轻松实现业务模型的快速落地与迭代,欢迎登陆体验!
UModelVerse控制台模型广场
官方表示DeepSeek-V3.2-Exp是一个实验性(Experimental)的版本,是迈向新一代架构的中间步骤。V3.2-Exp在V3.1-Terminus的基础上引入了DeepSeek Sparse Attention(一种稀疏注意力机制),针对长文本的训练和推理效率进行了探索性的优化和验证。
稀疏注意力机制(DSA)
DeepSeek Sparse Attention(DSA)首次实现了细粒度稀疏注意力机制,在几乎不影响模型输出效果的前提下,实现了长文本训练和推理效率的大幅提升。
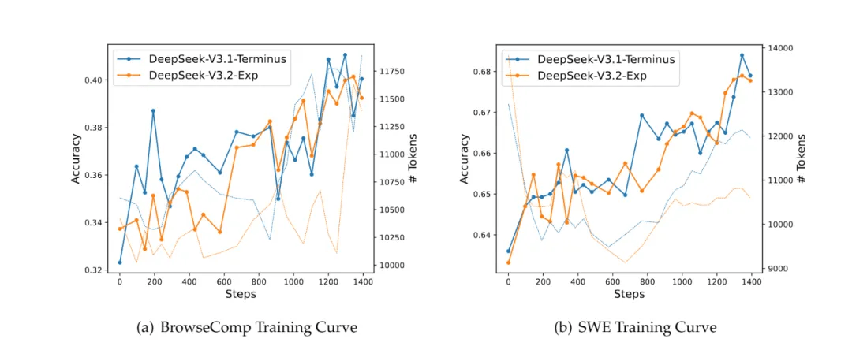
V3.1-Terminus和V3.2-Exp在BrowseComp和SWE Verified上的强化学习训练曲线,实线和虚线分别表示准确率和平均输出tokens
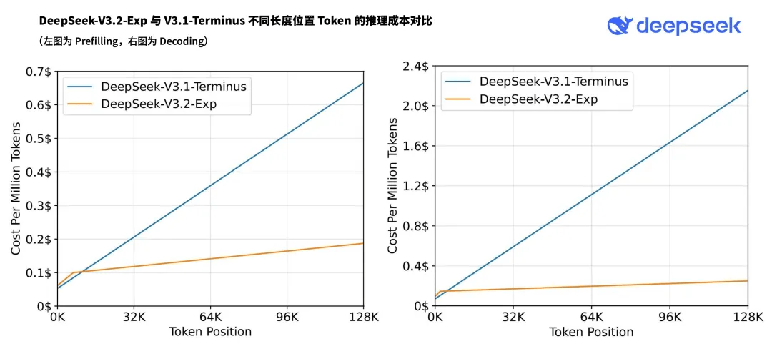
V3.1-Terminus和V3.2-Exp推理成本对比
与之前模型最大的不同在于,DSA不再要求每个Token关注序列中的所有其他Token,而是引入了一个名为「闪电索引器」(lightning indexer)的高效组件。这个索引器能以极快的速度判断,对于当前正在处理的Token,序列中哪些历史Token是最重要的。随后,模型仅从这些关键Token中筛选出少量(例如Top-k,取2048个)进行精细计算,从而在处理长文本时显著提升效率。更重要的是,这种设计在实现效率飞跃的同时,并未牺牲模型的核心性能。
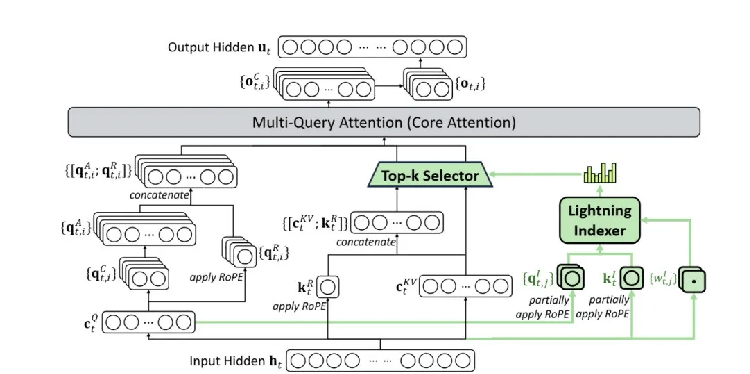
DeepSeek-V3.2-Exp的注意力架构
根据官方公布的评测结果,在与前代模型V3.1-Terminus严格对齐的训练设置下,V3.2-Exp在各大公开基准测试中的表现与前者基本持平。
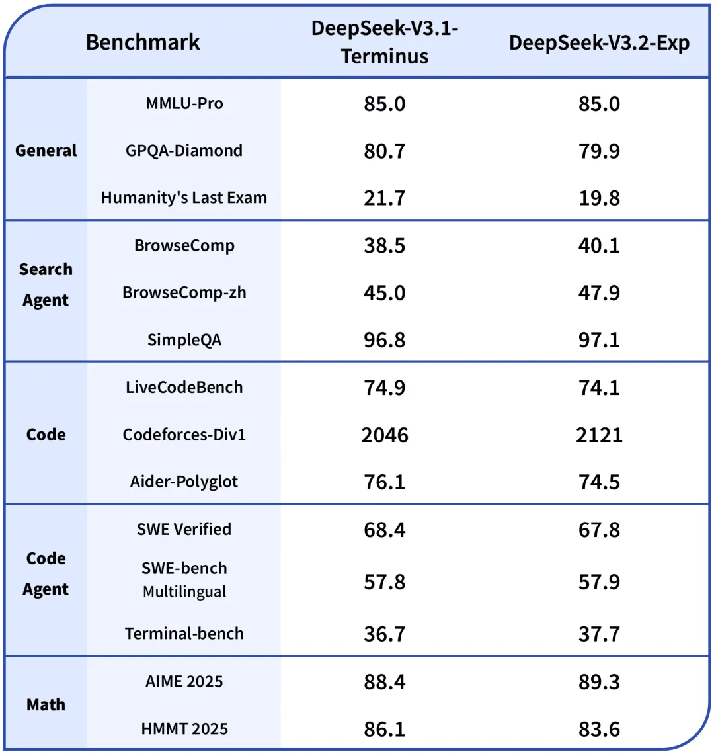
V3.1-Terminus和V3.2-Exp在各基准下测评对比
此外,为支持社区研究,DeepSeek还开源了新模型研究中设计和实现的GPU 算子,包括TileLang和CUDA两种版本。官方团队建议在进行研究性实验时,优先使用基于TileLang的版本,以便于调试和快速迭代。
得益于新模型服务成本的大幅降低,官方API价格也相应下调,新价格即刻生效。在新的价格政策下,开发者调用DeepSeek API的成本将降低50%以上。
登录UModelVerse一键调用

















