在 GenAI 的浪潮下,各行各业正迎来全新的变革,作为 AI 载体的智能硬件行业也不例外,一方面,AIGC 与机器人的结合,推动具身智能产业快速发展,科幻电影里善解人意的清扫机器人“瓦力”、医疗机器人“大白”正在走进现实。另一方面,以智能手表、智能眼镜、智能耳机为首的穿戴式智能硬件与多模态大模型的结合也成为当下的新趋势。
在2017年以天猫精灵、小爱同学、小度等语音助手驱动的智能设备被视为第一批 AI 硬件革命,这类智能设备虽然经过多年的市场教育已逐渐融入了我们的生活,成为不少家庭的语音助手,但其中 AI 的智能化还较为初级。近两年伴随 GenAI 的兴起,更智能化的多模态大模型赋予了智能硬件新的生命,带来全新的人机交互体验,催生智能硬件行业新的变革。
智能硬件+多模态大模型 穿戴式设备交互体验迎来变革
声网经过市场调研发现,目前多模态大模型在智能硬件场景的落地主要以智能眼镜、智能手表、智能耳机等穿戴式设备为主,同时在智能门铃、智能陪伴玩具等 IoT 场景也有一些应用。不同场景展现出的用户需求与场景特点存在一定的差异化,例如:
· 智能手表:智能儿童手表是多模态大模型最早落地 IoT 行业的硬件场景之一,目前 360儿童手表、小天才等儿童手表中已率先集成应用。流畅的 AI 互动问答可以填充儿童空闲时间,智能化的回答也为儿童带来了知识科普的价值,起到教育学习的辅助作用。同时,智能手表的屏幕较小,对语音交互的诉求更强,加入对话式 AI 显得更顺其自然。
· 智能眼镜:不同于将重点放在虚拟与现实结合的AR眼镜,智能眼镜更加注重通过 AI 提升语音交互能力,今年 Meta 联合雷朋推出的「Ray-Ban Meta」智能眼镜就是代表产品。通过在智能眼镜中加入摄像头、AI 等功能,用户可通过语音交互让眼镜来帮助工作&日程安排,或者开启百科问答、学习辅助、英文翻译、语音导航、超拟人情感陪伴及音乐娱乐等功能。
在 AI 与 RTC 能力的加持下,智能眼镜可以支持第一视角音视频回传(包含音视频通话、视频录制、直播等),还支持实时翻译、同声传译等场景,搭配手势识别,实现跨语言环境 的语义理解。

图:「Ray-Ban Meta」智能眼镜
· 智能耳机:智能耳机与大模型的结合主要集中在实时翻译、情感交流、录音转写等核心功能,在实时翻译方面,智能耳机目前主要应用在1对1翻译,支持双方对话过程随时发言,无需等待翻译完成或对方发言结束,适合双人会议、差旅、教学、社交等高频深度对话场景,代表产品有三星 Galaxy Buds 系列无线耳机、时空壶 W4 Pro等。同时,借助 RTC 的能力,在智能耳机中还能实现多人同频道、AI降噪等功能。
在情感交流方面,代表产品有当下热门的Ola Friend 智能耳机,该产品可实现英语陪练、旅行导游、情感交流等功能。开发者如想快速上线此类型的智能耳机,声网可以提供快速、已用、完整的解决方案,并采用了灵活可扩展的 AIAgent架构,具备工作流编排能力,开发者与企业可自主选择 LLM 等组件,根据特定需求定制和扩展 AI 驱动的实时互动体验。
· 智能门铃:在智能门铃等IPC场景,加入 AI 大模型的能力,可通过摄像头实时识别并理解视频内容,实现设备无人值守场景下的自定义交互,如:外卖、快递上门,在家中无人时,门铃可自动识别并应答,指导快递员将货物放到指定位置。
此外,在GenAI 的趋势下,IoT 行业还出现了智能陪伴机器人、智能儿童毛绒玩具、智能戒指等一系列智能硬件场景,带来不同硬件终端下的 AI 语音交互体验。
声网 AI x IoT 智能硬件解决方案 低功耗、低延时、低成本
声网作为全球实时互动云行业的开创者,一直在探索 GenAI 与 RTE 结合带来的体验提升和场景创新,此前发布了实时多模态对话式 AI 解决方案,在此基础上,针对 IoT 行业的特殊性,声网探索出了AI x IoT 智能硬件解决方案,该方案能够在低功耗、低算力芯片上快速实现大模型的接入,具备低延时实时互动、低成本灵活适配的特性,通过丰富的功能在智能硬件场景中构建真实、自然的 AI 语音交互体验。
例如对交互延迟进行优化,语音交互延时低至1s内;支持多模态 AI 语义识别和理解;支持 AI降噪,保证清晰的语音交互、支持小包体、低内存、低功耗;适配支持70+主流、高性价比的芯片等,帮助开发者与企业快速构建适配自己硬件的 AI 实时语音对话服务。
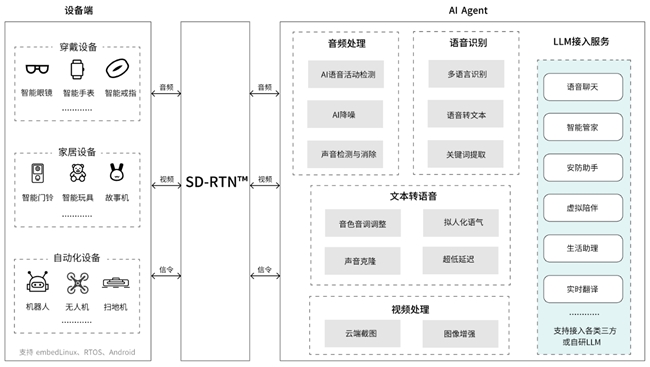
图:声网 AI x IoT 智能硬件解决方案架构图
1、毫秒级人机交互体验:声网 AI x IoT 智能硬件解决方案进一步优化了端到端互动体验,实现人与设备之间基于 LLM 的毫秒级互动体验。通过在客户端进行低延迟的音频采集和播放、借助声网自研的 SD-RTN™ 实时传输网络实现全球范围的低延时 RTC 传输,并进一步通过更快速的 LLM 推理首字耗时、低延迟流式 TTS、同机部署等一系列技术手段,保证对话的实时性与流畅性。
2、文本/图像/音频/视频的多模态交互:在智能硬件场景,声网的解决方案同样支持文本/图像/音频/视频的组合输入&输出,同时开发者与企业也无需额外集成STT、TTS 等模块化组件,一套方案就能快速构建 AI 实时语音对话服务。
3、聚焦关键信息,提升语义理解度:在 GenAI 场景,能否支持随时打断也成为衡量大模型智能化的重要指标,声网的解决方案也支持先进的 AI-VAD 技术,可实现灵敏的自然语音打断,模拟人类对话的自然流动,让对话更加真实、自然。
4、AI降噪保障语音对话清晰、顺畅:针对语音对话中经常会出现的噪音、回声等问题,声网拥有行业领先的音频 3A 能力,通过AI噪声抑制、背景人声过滤、音乐检测/过滤等算法,确保人与 AI 的对话不受环境干扰,始终保持顺畅。
5、实现多模态 AI 能力普适:实现任意可视设备的智能化体验:在硬件场景构建音视频互动需要特别注意 SDK 对芯片、系统的适配性以及包体的体积等。声网的解决方案适配支持 70+ 主流、高性价比的芯片/模组,例如:展锐 Cat.1系列芯片、乐鑫 ESP32-S2/S3、BK 7256、BK7258、杰理AC7916、博流BL808等 RTOS 芯片,以及高通、联发科、君正、Sigmastar、全志、海思、Mstar 等 70+ Linux 芯片。
集成包体积增量也<400KB,支持在 RTOS、embedLinux 等低功耗系统流畅运行,同时 SDK 还支持 PCM、G711U/A、G722、AAC、OPUS 等多种音频格式。
如您想进一步体验 Demo或者接入 声网的AI x IoT 智能硬件解决方案,可在声网公众号找到这篇文章,扫描文章底部的二维码联系。















