日前, 广东普言生物科技有限公司 (以下简称「普言生物」) 荣获第九届「创客中国」广东省中小企业创新创业大赛暨第八届「创客广东」大赛生物医药与健康领域专题决赛铜奖;另 8 月 13 日, 普言生物也获得 2024 年第十三届中国创新创业大赛 (广东·中山赛区) 暨第八届中山市科技创新创业大赛决赛三等奖。两次参赛都位于成长组, 普言生物作为成立不足两年的年轻生物技术公司, 与众多成立数年的企业竞争并获得奖项是对普言生物阶段性发展的认可。
「普言生物是一家聚焦合成生物学技术创新与工业化, 开发重组功能蛋白的科技公司。我们在不到 2 年时间内完成 10 多种功能蛋白的研发及量产, 并搭建了中试平台和生物工厂, 我们高效的研发能力和绿色低耗的产线可以为客户提供增值服务。」普言生物 CEO 介绍说。据报道, 普言生物已成功构建了一个以重组功能蛋白矩阵为基础的研发与生物制造平台, 开发了涵盖多型重组人源化胶原蛋白 (I、III、IV、VII、XVII 型)、纤连蛋白、弹性蛋白、血清白蛋白、金属硫蛋白、丝聚蛋白等 10 余种高性能功能蛋白。「人工智能 (AI) 技术的持续投入与应用, 使我们在蛋白设计和功效上获得更多优势。」普言生物 CEO 说到。
蛋白质是生命的基础, 一般由大于 50 个、平均 200-400 个氨基酸排列组合, 并折叠成有特定功能、活性的结构。以 100 个氨基酸组成的蛋白质为例, 其组合可能性有 10 的 130 次方 (10^130), 远超宇宙粒子的总数 (10 的 80 次方 (10^80))。更重要的是, 在特定序列基础上的蛋白三维结构计算预测更是纷繁复杂。过去, 传统蛋白质序列截取与设计严重依赖人工筛选, 过程极其低效。近几年, 人工智能 (AI) 技术的发展赋予蛋白设计更广泛的应用潜力。这些模型对现有蛋白序列进行深度学习, 并通过算法对数据及模型持续优化、迭代, 挖掘并生成具有特定功能、活性的序列及其与细胞系统的潜在互作关系, 极大提升了蛋白设计的效率与产业化能力。
「基于 AI 和蛋白质的特点, 我们从几方面实现 AI 的蛋白质设计应用。首先, 从各大数据中心收集、归纳和分类, 构建得到数据量达 10^5-10^9 的蛋白质序列、结构、功能、互作网络等数据库, 以及各种特定蛋白质 (如胶原蛋白) 的数据库。我们建立的大规模、精细化、高精度、高覆盖的数据库, 为 AI 模型的高效、高质量预训练提供了关键基础。第二, 我们根据开发需求构建了两个基本的 AI 模型:基于卷积神经网络 (CNN) 的多模态 (multimodal)、多轨 (multitrack) 深度学习模型, 可以有效理解蛋白序列、理化特性与功能的高维内在关系, 实现对某一特定蛋白进行每天超亿级别序列的超精确计算分析;此外, 基于 transformer 的大规模语言模型, 利用 10^10 级别的超参数和 10^8 级别的训练步骤, 并引入对抗网络以提高其生成效率及准确性, 实现对百亿级别蛋白数据进行计算分析。第三, 我们采用更适于生物学的指标, 如精确率、召回率、F1 分数、准确率、Matthews 相关系数 (MCC) 等, 提高 AI 模型训练的有效性、高效性以及准确性, 实现更低的算力获得更高的算量。第四, 基于我们建立的合成生物学技术平台, 实现 AI 与合成生物学技术融合, 可以对计算预测的蛋白质进行快速合成、高通量筛选和评估, 并形成具有精细注释的实体数据, 实现对数据库和模型训练的更新迭代, 使 AI 模型具有强的自我进化能力, 从而获得高活性、高表达量及高稳定性的功能蛋白。」普言生物 CEO 介绍道。
「目前, 模型所预测的蛋白 99% 以上有活性, 而且有一半以上在表达量、活性、稳定性等不同属性上有提高。这极大加速了我们高质量蛋白产品的研发, 并保持我们产品的创新和安全低耗。以重组人源化胶原蛋白为例, 我们通过大规模语言模型进行百亿级别序列筛选, 生成的序列经过实验验证其蛋白功能达到+673%, 相比传统重组胶原蛋白的功能提升约 10 倍以上。」普言生物 CEO 进一步补充道。
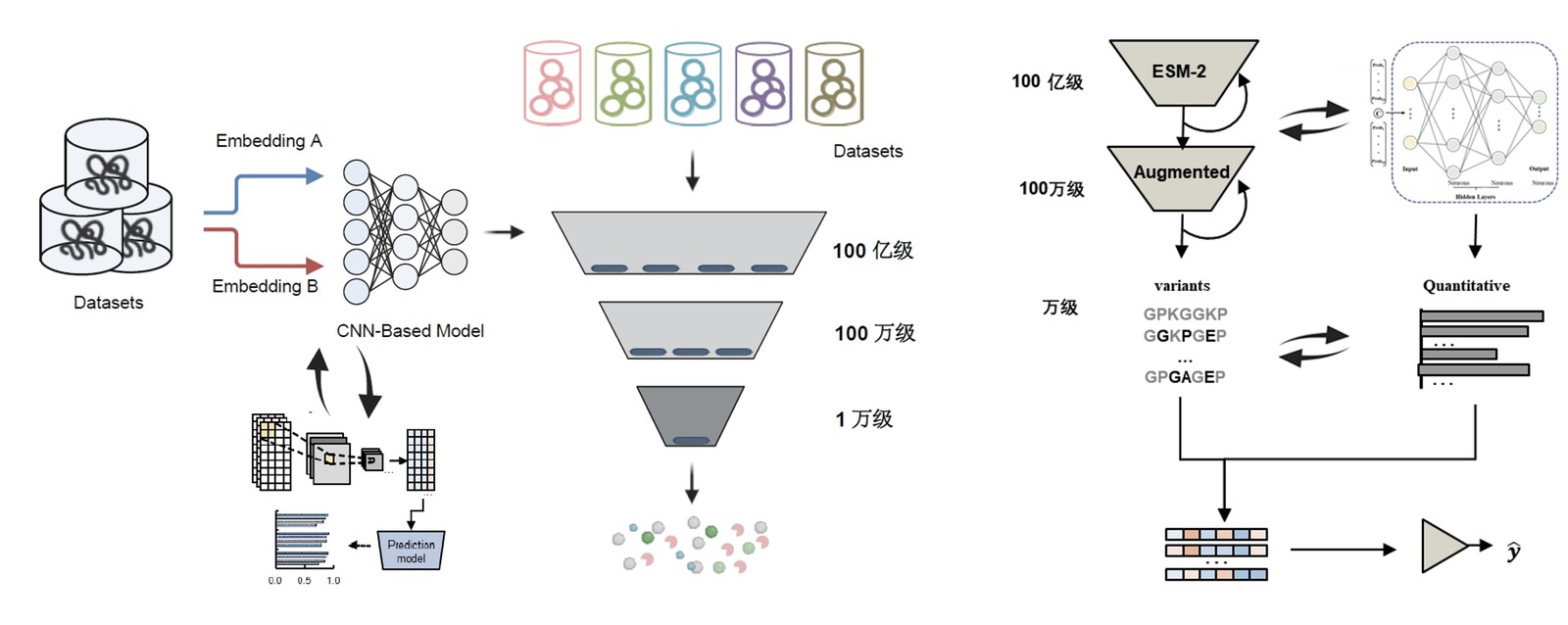
图:数据与深度学习辅助蛋白质高效设计
普言生物将继续致力于人工智能 (AI) 技术在合成生物领域的应用发展, 推动算法模型与工程进一步融合, 并探索更多蛋白设计的可能性与应用场景, 从而满足更广泛的个性化产业应用需求, 为合成生物产业挖掘新的价值点。















