小巧、快速且具备多模态能力,Gemma 4 可将强大的推理、编码和多模态 AI 直接带到 NVIDIA RTX PC、DGX Spark 和边缘设备上。

开放模型正在推动新一轮端侧 AI 浪潮,将创新从云端扩展到日常本地设备。随着这些模型不断进步,其价值愈发取决于能否访问本地实时上下文,从而将有价值的洞察转化为行动。
为顺应这一转变,Google 的 Gemma 4 家族全新引入了一系列小巧、快速且具备多模态能力的模型,能够在各类设备上实现高效本地运行。
Google 与 NVIDIA 合作,针对NVIDIA GPU 优化了Gemma 4 ,在多种系统上实现高效性能。从数据中心部署到 NVIDIA RTX 驱动的 PC 和工作站,再到 NVIDIA DGX Spark 个人 AI 超级计算机以及 NVIDIA Jetson Orin Nano 边缘 AI 模块。
Gemma 4:为 NVIDIA GPU 优化的紧凑型模型
Gemma 4 开放模型家族的最新成员涵盖 E2B、E4B、26B 和 31B 变体,专为从边缘设备到高性能 GPU 的高效部署而设计。
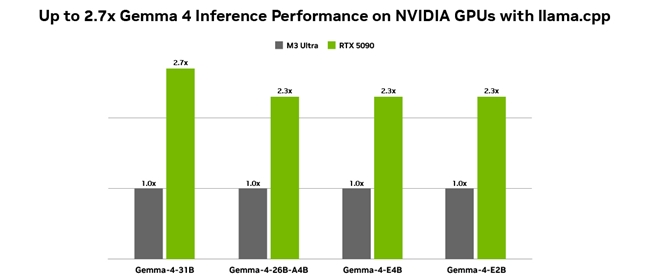
所有配置均采用 Q4_K_M 量化、BS = 1、ISL = 4096 和 OSL = 128,在 NVIDIA GeForce RTX 5090 和 Mac M3 Ultra 台式机上进行测试。Token 生成吞吐量基于 llama.cpp b7789,使用 llama-bench 工具测试。
新一代紧凑型模型支持多种任务,包括:
● 推理:在复杂问题求解任务中表现强劲。
● 编码:面向开发者工作流的代码生成与调试。
● 智能体:原生支持结构化工具调用(函数调用)。
● 视觉、视频和音频能力:支持物体识别、自动语音识别以及文档或视频智能等丰富的多模态交互。
● 交错式多模态输入:可在单个提示词中以任意顺序混合文本和图像。
● 多语言:开箱即用,支持超过 35 种语言,并在超过 140 种语言上进行预训练。
E2B 和 E4B 模型专为超高效、低延迟的边缘推理而打造,可在包括 Jetson Nano 模块在内的多种设备上以接近零延迟的方式完全离线运行。
26B 和 31B 模型专为高性能推理和以开发者为中心的工作流而设计,非常适合代理式 AI 任务。这些模型以便捷的方式提供经过优化的、业界领先的推理能力,可在 NVIDIA RTX GPU 和 DGX Spark 上高效运行,为开发环境、编码助手和智能体驱动的工作流提供支持。
随着本地代理式 AI 持续升温,OpenClaw 等应用正让 RTX PC、工作站和 DGX Spark 上全天候在线的 AI 助手成为现实。最新的 Gemma 4 模型兼容 OpenClaw,允许用户构建能够通过上下文调用个人文件、应用程序和工作流的本地智能体,以实现任务自动化。查看页面了解如何在 RTX GPU 和 DGX Spark 上免费运行 OpenClaw,或查看 DGX Spark OpenClaw playbook。
查看 Google DeepMind 公告博客,了解 Gemma 4 家族最新成员的更多信息。
开始上手:在 RTX GPU 和 DGX Spark 上运行 Gemma 4
NVIDIA 已与 Ollama 和 llama.cpp 合作,为各个 Gemma 4 模型提供最佳本地部署体验。
要在本地使用 Gemma 4,用户可以下载 Ollama 来运行 Gemma 4 模型,或安装 llama.cpp 并结合 Gemma 4 的 GGUF Hugging Face checkpoint 使用。Unsloth 提供首日支持,通过 Unsloth Studio 提供经过优化和量化的模型,以实现高效的本地微调和部署。现在即可开始在 Unsloth Studio 中运行和微调 Gemma 4。
在 NVIDIA GPU 上运行 Gemma 4 家族等开放模型能够实现最佳性能。NVIDIA Tensor Core 可加速 AI 推理工作负载,从而为本地执行提供更高吞吐量和更低延迟。CUDA 软件栈可确保与主流框架和工具广泛兼容,使新模型从发布首日就能高效运行。
这套组合使得 Gemma 4 等开放模型可在广泛系统上扩展部署,从边缘侧的 Jetson Orin Nano 到 RTX PC、工作站和 DGX Spark,无需深度优化即可覆盖。
查看 NVIDIA 技术博客,了解如何在 NVIDIA GPU 上快速上手 Gemma 4 的更多细节,并进一步了解 NVIDIA 在开放模型方面的工作。
#别错过: NVIDIA RTX AI PC 的最新进展
请查看 RTX AI Garage 博客,了解 NVIDIA GTC 期间发布的一系列关于代理式 AI 的公告,例如面向本地智能体的新开放模型,以及针对 Qwen 3.5 和 Mistral Small 4 的优化。
NVIDIA 最近推出了 NVIDIA NemoClaw,这是一套开源技术栈,可通过提升安全性并支持本地模型来优化 NVIDIA 设备上的 OpenClaw 体验。
Accomplish宣布推出 Accomplish FREE,一款免费版的内置模型的开源桌面 AI 智能体。它使用 NVIDIA GPU 在本地运行开放权重模型,同时通过混合路由器在本地 RTX 硬件与云端之间动态平衡工作负载,无需调用 API Key,即可实现快速、私密、零配置的执行体验。
NVIDIA RTX AI PC的相关信息请关注微博、抖音及哔哩哔哩官方账号。
关于NVIDIA
NVIDIA是加速计算领域的全球领导者。















