在实时数字人赛道,开发者们曾长期面临一个困扰:追求高画质就需要具备昂贵的 H800 集群,追求低成本就得忍受“面瘫”和画面崩坏。这一行业痛点限制了技术的普及,阻碍了无数创意应用的落地。面对这道看似无解的难题,Soul创始人张璐带领团队深入技术底层,试图在算力成本与渲染效果之间寻找新的平衡点,致力于打破高性能与低门槛之间的壁垒。
就在继开源了 14B 参数的实时数字人生成模型 SoulX-FlashTalk 之后,时间来到2月12日,Soul App AI团队再次放大招,正式推出了名为SoulX-FlashHead的全新力作。这款仅有1.3B参数的轻量化模型,简直就像是给行业带来了一场及时雨,它竟然能够在单张普通的消费级显卡(比如RTX 4090)上,跑出高达96FPS的工业级速度,同时还保持着令人惊叹的高质量画质,为整个行业提供了一套全新的、切实可行的实时数字人解决方案。

说到SoulX-FlashHead的核心亮点,那可真不仅仅是“实时”那么简单,它更像是一把开启“算力自由”大门的钥匙。其 Lite 版本专为高速率设计,单张4090显卡就能轻松飙到96FPS,而且显存占用低至6.4G,最高还能支持3路并发。而Pro版本则是在高画质上做到了极致,虽然单张5090显卡推理帧率为16.8FPS,但只要双卡并联就能实现实时的 25fps+流畅体验,更重要的是,它的FID视觉质量指标和唇形一致指标在权威评测中达到了SOTA(目前最佳)水平,甚至超越了许多参数量更大的模型,彻底解决了“小模型就没好画质”这个行业老大难问题。
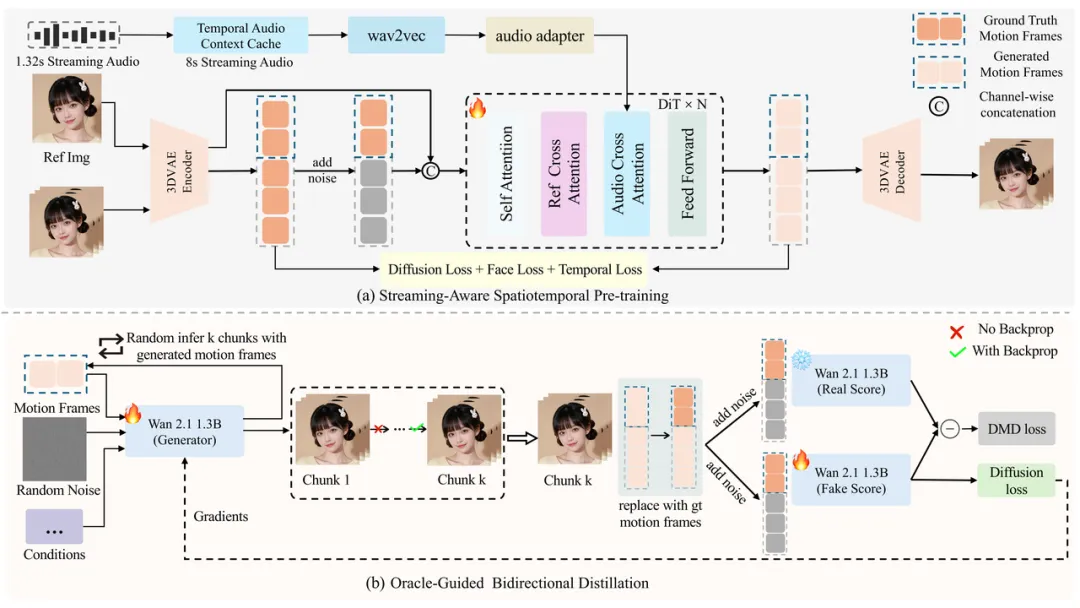
那么,究竟是如何让这区区1.3B的小模型实现“以小博大”的呢?这背后其实藏着不少黑科技。首先,SoulX-FlashHead创新性地引入了被称为训练“先知”的双向蒸馏机制。针对长视频生成中容易出现的“身份漂移”痛点,它利用Ground Truth作为先知锚点进行强约束,就像给模型装了一个高精度的校准器,无论视频多长,人物特征都能稳如泰山。其次,为了解决流式生成中因音频切片过短导致的口型抖动问题,团队设计了独特的“8秒记忆”时序音频上下文缓存(TACC),强制模型缓存8秒的历史音频特征来补偿上下文缺失。当然,这一切的基石还在于其自研的VividHead高质量数据底座,团队从超过10,000小时的素材中,经过严苛的筛选和清洗,最终精炼出782小时最纯净的音画数据,为模型提供了最优质的“养料”。
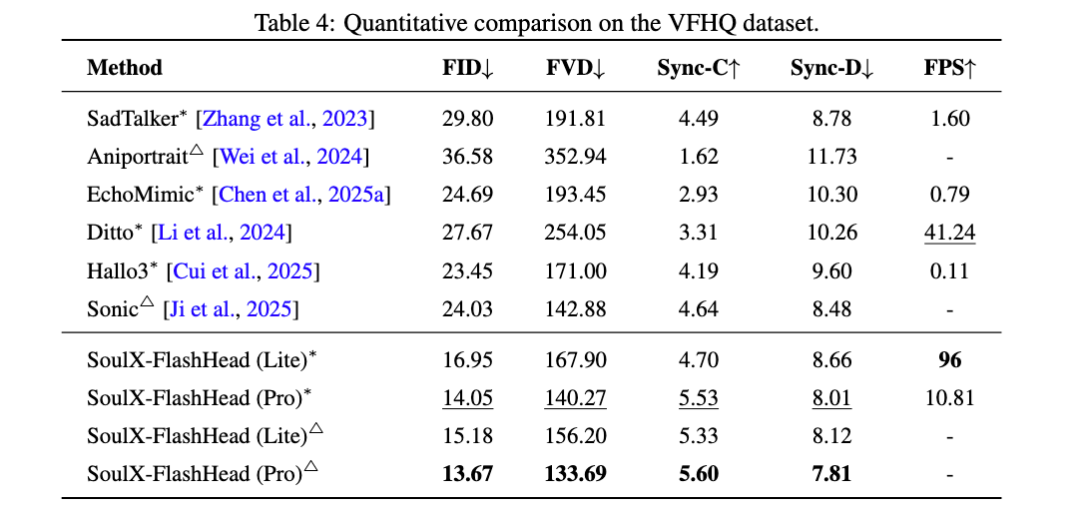
在客观表现方面,SoulX-FlashHead 的成绩单也是相当亮眼。在HDTF与VFHQ两大权威数据集的实测中,Pro版本以8.31的FID和103.14的FVD成绩刷新了高清视频评测纪录,视觉细腻度甚至超过了一些“大块头”模型。而在面对野外复杂场景时,凭借独创的缓存策略,其Sync-C得分高达5.60,大幅领先此前相关工作,彻底告别了对不上口型的尴尬。更令人咋舌的是其速度,仅凭1.3B的轻量化体量,Lite版本在单张RTX 4090上就跑出了96 FPS的吞吐量,这不仅是实时基准的近4倍,推理效率更是行业同类主流模型的100倍以上,简直就是速度与激情的完美结合。
这一系列突破不仅是技术参数上的胜利,更是Soul创始人张璐带领团队对“技术普惠”理念的生动实践。随着更多开发者加入这一生态,实时数字人将不再是大厂的专属玩具,而是成为每个人都能轻松调用的创意工具,开启人机交互的无限可能。















