随着AI技术与产业加速迭代,异构加速设备与大模型层出不穷,为企业智能化转型注入动能的同时,也给AI基础设施带来两大核心挑战:
* 算力适配滞后:全球产业链重构背景下,GPU厂商、架构、型号持续迭代,数据中心多元异构成为常态,AI基础设施难以快速跟进最新算力迭代,适配周期长;
* 生态兼容不足:新型GPU上市后,芯片厂商会定制适配推理引擎以支持主流大模型快速部署,而传统AI基础设施难以同步匹配最新生态,导致算力无法快速转化为生产力。
针对上述问题,浪潮云海InCloud AIOS秉承“分层解耦、开放兼容”核心理念,创新推出异构加速设备动态扩展方法,设计了面向异构算力的推理引擎快速适配框架,实现新架构、新型号加速设备的小时级兼容,通过智能调度让已兼容模型高效运行,打通从算力到智能生产力的“最后一公里”,成为AI时代企业异构算力管理的最佳伙伴。
异构加速设备动态扩展:小时级兼容新算力,打破异构壁垒
浪潮云海InCloud AIOS基于device-plugin机制构建异构设备扩展框架,向下适配各厂商设备管理模块,向上衔接产品GPU管理功能。
深度遵循PCI设备规范,在宿主机内核态与用户态协同层面构建精细化设备探测引擎:通过通用唯一PCI设备标识符(Device ID/Vendor ID) 实现跨厂商GPU的自动化发现与精准识别,解决传统方案中识别效率低、识别不准确的问题;以设备号为索引主键,关联提取GPU 的硬件拓扑、算力规格、显存容量与带宽、虚拟化能力等通用属性,将其抽象为标准化的节点标签(Node Label)并上报至Kubernetes控制平面,为算力资源调度提供依据。
针对多厂商GPU数据格式异构、能力描述碎片化的问题,首创面向AI负载的GPU统一能力模型,通过抽象层设计,将不同生态的GPU异构数据(如算力单元、显存带宽、指令集支持)与差异化能力映射为标准化数据结构,基于该模型实现“统一节点能力画像”的精细化资源表征。
在产品界面依托统一能力模型,实现GPU资源的全景统计、可视化呈现与智能化调度,打破传统方案的割裂管理模式,大幅缩短异构GPU兼容性适配周期,解决统一管理难题。
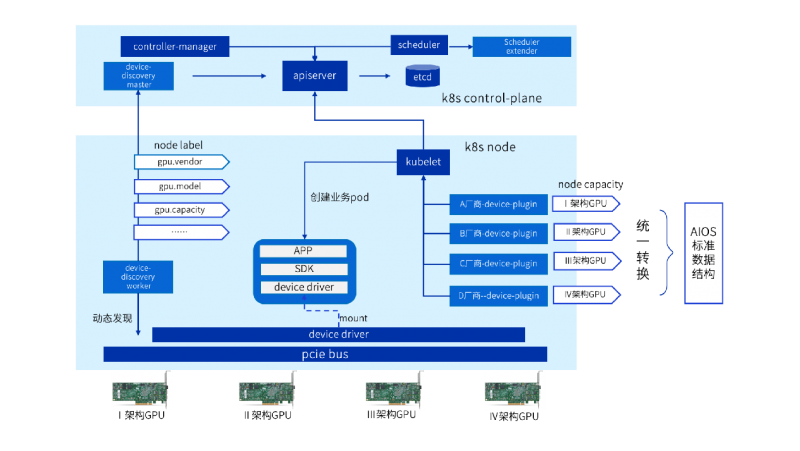
异构加速设备动态扩展方法
推理引擎快速适配框架:快速适配生态,高效部署模型
不同类型模型(文本生成、多模态、嵌入式等)对推理引擎需求各异,且GPU与推理引擎版本强依赖,给模型部署带来挑战。浪潮云海InCloud AIOS以K8s为底座,设计推理引擎快速适配框架,实现异构GPU与推理引擎的高效兼容。
构建统一的“模型-GPU-推理引擎”映射模型,通过配置化操作完成不同类型模型在异构 GPU 上的推理引擎版本匹配,为模型加载决策提供清晰依据。
在K8s层面统一封装工作负载接口,自研模型加载调度器作为推理引擎启动的统一入口,提供模型文件分发状态判断、环境变量读取、启动参数配置、本地软链接创建等功能,彻底屏蔽各类推理引擎的参数差异,降低使用门槛。
复用已有的GPU快速适配能力,扩展K8s调度框架,根据GPU型号将推理引擎调度到最佳的主机上加载模型,通过svc方式使用OpenAI格式接口对外提供推理服务。
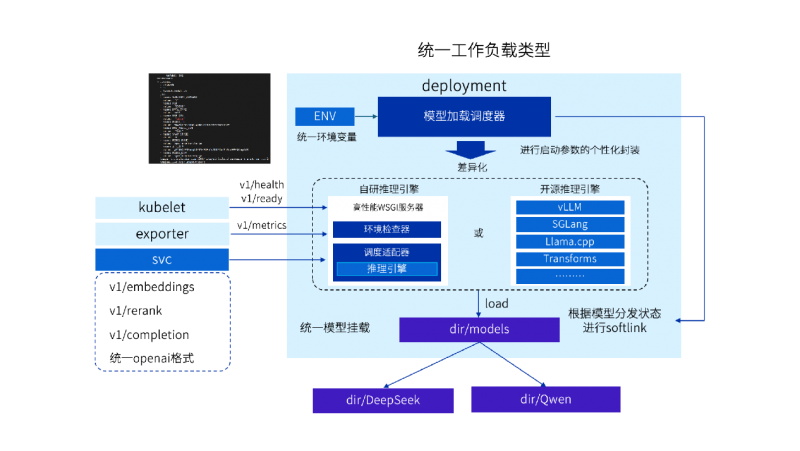
推理引擎快速适配框架
零代码改动,一小时完成千亿模型适配
通过两大核心技术创新,浪潮云海InCloud AIOS已实现多厂商、多架构GPU型号适配,支持自研及vLLM、SGLang等面向不同GPU的推理引擎版本,充分验证了“一云多算”的实战能力。
在某政府行业客户现场,浪潮云海 AIOS 在零代码改动的前提下,仅用一小时就完成某架构最新型号 GPU 的兼容与推理引擎适配,以分布式方式成功运行DeepSeek最新发布的千亿参数模型,提供稳定可靠的模型服务,获得客户高度认可。
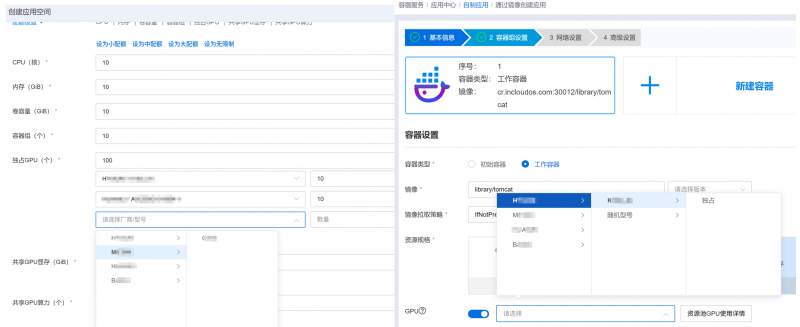
客户现场新适配的GPU与产品能力无缝衔接
开放兼容,让 AI 算力游刃有余
AI正从工具加速进化为“数字劳动力”,异构算力的高效管理成为企业智能化转型的关键。浪潮云海InCloud AIOS通过“异构加速设备动态扩展+推理引擎快速适配”的双重创新,打破了算力与生态的兼容壁垒,实现新算力小时级接入、模型高效部署,让企业无需为异构兼容发愁,专注于AI应用创新。
未来,浪潮云海InCloud AIOS将持续聚焦推理性能优化与算力资源使用率提升,不断深化软硬协同能力,为行业客户提供高效稳定的AI基础设施,助力企业在异构算力时代从容驾驭AI浪潮,实现智能化转型游刃有余。















