从流批一体、湖仓一体、NoETL、数据中台到DataOps,现代数据分析领域热词迭出,企业如何抓住本质,经营数据生产力以提质增效?
9月26-27日,ArchSummit全球架构师峰会杭州站举办,网易副总裁、网易杭州研究院执行院长、网易数帆总经理汪源受邀在会上发表主题演讲,深入浅出地剖析了现代化数据分析架构中最值得关注的三条主线,包括统一的基础设施、统一的中间层和统一的数据资产,并介绍了国内外的相关技术实践。

统一的基础设施:流式湖仓,Iceberg+Arctic将成核心
统一的基础设施要解决四大问题:湖仓一体、流批一体、标准格式和存算分离——不仅是文件格式,还包括表格式。汪源表示,理想的统一基础设施是流式湖仓的基础设施,即湖仓和流批都做到一体。除了最底层的对象存储,目前已有可用的开源实现。
统一的基础设施包括六层架构。最底层是存储层,往上是Parquet文件格式层,中间加了缓存加速层,用来弥补上层需求和底层对象存储之间的性能差距,现在出现的有Alluxio、JuiceFS、CurveFS,其中CurveFS是网易数帆开源的一个文件存储系统。
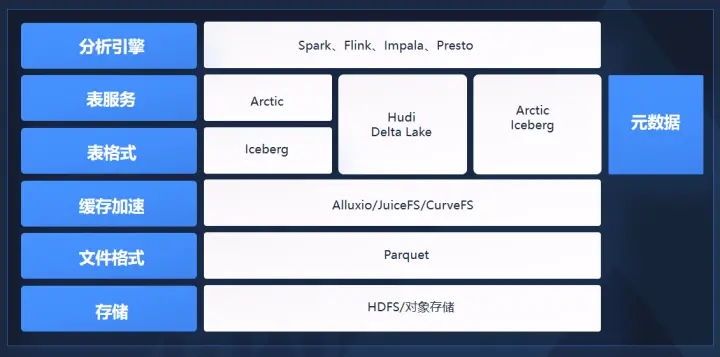
最核心的是最近两三年出现了两个新的层次,一个是表格式(table format),如Iceberg、Hudi,一个是表服务(table service),如Arctic。这两个层次能够让底层大数据体系支持湖仓一体、实时更新、版本一致性、ACID等等,之前的大数据没有这些功能,所以它无法做一些实时的分析服务,只能做T+1的分析。最上层是分析引擎层。
汪源认为Iceberg是最有希望成为table format标准的项目。Iceberg从数据层面提供了ACID的能力,并且可以读到任何时间点的数据;第二个从元数据层面解决了HMS性能瓶颈,把原来集中式的元数据变成了分布式的元数据,并且相当于给数据构建了一个多级的索引,能够支持高级过滤,这能解决很多问题。比如大数据场景常见千万甚至亿级文件的查询,基于Hive的查询启动可能要花20分钟,而Iceberg可以做到一分钟以内,这是一个非常夸张的进步。
Arctic由网易数帆于2022年8月宣布开源,但在网易数帆内部研发已经将近三年。Arctic主要用来帮助Iceberg把整体的技术体系构建完整,因为Iceberg只是一种格式,无法单独形成面向分析性能最优化的状态。Arctic首先提供了基于Iceberg的自优化的能力,以及upsert的功能,支持高效的数据更新。其次支持流批一体,流表和批表定义一致,可以复用。最后是兼容Hive和Iceberg,从而可以快速落地。
汪源认为,今天由Iceberg和Arctic共同构建的这一层会成为一个新的事实的标准,在它下面有不同的存储,在它上面有不同的计算体系。“这个中间基本上胜出的只有一家,不可能有多家,否则这个技术栈就混乱了。”
统一的中间层:数据仓库+HeadlessBI
数据分析的过程,理想的状态是理论大师们规划的路线:在数据仓库里面做好了所有的数据转化,每一个团队用很好的BI工具只做数据的展现和交互,所有的计算逻辑应该都在数仓里面完成。但实际上每一个团队都会在自己的BI里面去做很多的计算逻辑,这是数据仓库的计算逻辑不够用,导致计算逻辑分散的问题。汪源指出,大家在不同的BI产品中看到的数据口径和结果的差异,就是由分散的计算逻辑带来的。
解决该问题的“中国方案”是数据中台,通过OneData、OneService、OneID,解决指标口径不一致的问题,所有的口径定义、计算逻辑都在中台做好。数据中台包括了数据仓库,在数据仓库定义了一套规范的指标层,包括原始指标、派生指标、复合指标。上面是数据服务层,提供所有对外的数据。同时又引入了数据治理来保证中台输出的数据符合质量和安全要求。

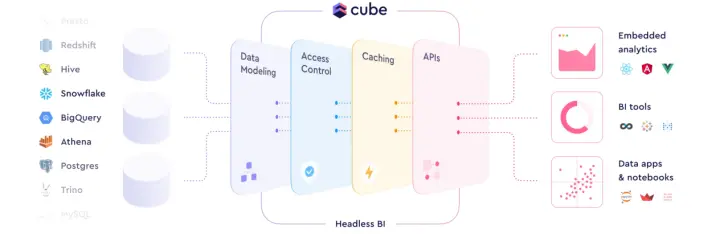
国际方案包括三个核心概念:Semantic Layer、HeadlessBI和Metric Layer。汪源认为最贴切的描述是HeadlessBI,以国外的Cube产品设计为例,数据输入来自左边的各种数仓,中间HeadlessBI要做的是数据建模、安全相关的访问控制、性能加速,最后以API的方式提供给右边的下游消费者,主要是BI工具以及嵌入式的分析。
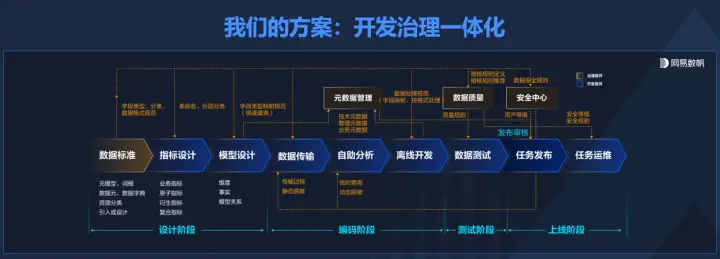
在这个方向上,网易数帆强调的是开发和治理一体化,在建数仓、建指标等开发活动的过程中把数据治理同步完成,让指标、模型等持续保持高质量。此前,网易数帆发现很多客户先找开发的方案来做开发,做完之后发现数据质量不佳,又去做数据治理的项目。汪源表示,在开发环节同时把开发治理做好了,就不会有这样的后遗症。
汪源对统一的中间层的期待,包括数据仓库和HeadlessBI两层,后者能做建模,包括指标,做权限、加速和服务,同时把开发和治理一体化,通过统一的模型指标计算逻辑和口径,实现事前事中事后的持续治理。这样BI层可以真正聚焦在展现和交付上,汪源将其命名为“NecklessBI”,与HeadlessBI对应。

汪源还强调,在此过程中,ETL不会被消除,它只能被转移或隐藏,因为从数据源到分析所需要的数据一定是有很多不匹配的,比较现实的是做ETL的自动化,即AutoETL。
统一的数据资产:Data Fabric已落地
数据资产管理面临的问题,是数据找不到,找到了看不懂,看了之后信不过、不敢用,管不牢等。汪源认为比较可行的思路就是分析机构提出的Data Fabric,它的目的是实现数据的整合利用,它是一个架构思想或者设计理念,并不绑定一个特定的技术实现。

Data Fabric和其他数据整合利用的方式有明显的区别:数据仓库或者数据中台,比较强调数据的集中,同时也强调数据比较深度的预加工。数据湖强调数据的集中,但是它强调数据不要做太多的预加工,应该按照原始的数据格式都存在湖里面,需要的时候再把它拿出来处理。Data Fabric则强调元数据的集中。
Data Fabric的实际落地需要构建四个方面的核心能力,包括连接数据源、主动元数据(active metadata)、数据虚拟化和逻辑数据湖。汪源认为数据虚拟化能最大程度发挥Data Fabric的能力,因为它能够在数据没有完成集中之前就能够做一定程度的利用,但并非所有的数据分析都可以基于数据虚拟化来做。网易数帆已经落地的逻辑数据湖,也是Data Fabric的一种实现,它从逻辑上看是一个湖,但是从物理实现上数据还是分散存储在Hadoop、Oracle、MySQL等系统里面。
总结
总体来说,现代数据分析技术的三大主题,第一个是构建一个统一的基础设施,能够支撑实时数据更新与消费,并且是开放、低成本的流式湖仓基础设施。第二个是统一的中间层,包括数据仓库和HeadlessBI两个层次,要做到统一的模型、指标、计算逻辑和口径,并实现事前事中事后持续的数据治理。第三个是统一的数据资产,目的是企业全域数据资产的高效的发现、整合和管理,它在实现上能够兼容各种风格的数据处理技术。
“我希望整个行业能够往这些方向去聚焦,不要产生太多的相互割裂的概念。”汪源说。















